Экибаны из осенних листьев: Поделки-аппликации из осенних листьев для детей
Поделки-аппликации из осенних листьев для детей
Осень, хрустят под ногами опавшие листья… Как же жаль эту желто-красную увядающую красоту, крошащуюся и втаптываемую в грязь. Вот листочек березки — нежно желтый, зубчатый, вот ольхи — ребристый, а вот рябинки — семейка длинных листочков на тонкой ножке. Давайте возьмем их домой и сделаем красивые осенние поделки, аппликации. Еще нам нужен будет листочек цветного картона для фона и клей, чтобы приклеить листики.
Как делать аппликацию из осенних листьев
Осенние листочки, высохшие на улице — не ровные и довольно хрупкие, поэтому для начала засушим листья сами. Находим только что опавшие, яркие и красивые, не поврежденные листья, и складываем их между листами какой-нибудь толстой книги. Книгу кладем под пресс (под что-нибудь тяжелое). Через неделю или даже раньше ровные осенние листики для аппликации готовы, их можно легко наклеить на бумагу или картон клеем ПВА.
Последовательность действий
Настоящий художник видит в природе живые образы, вот и мы пофантазируем. Выложим перед собой все наше собранное и высушенное богатство и посмотрим, что на что похоже. Берите подходящие листья и раскладывайте на картоне, пока не получится картина. Приклеивать пока не нужно, сначала просто разложите, пока вас не начнет все устраивать.
Выложим перед собой все наше собранное и высушенное богатство и посмотрим, что на что похоже. Берите подходящие листья и раскладывайте на картоне, пока не получится картина. Приклеивать пока не нужно, сначала просто разложите, пока вас не начнет все устраивать.
Когда картина доведена до идеала, можно приклеивать. Берем по одному листику, запомнив, где он лежал, намазываем его обратную сторону, клеим на место. Если аппликация многослойная, сначала приклеиваем нижние листья, затем слой верхних. Поделка готова! Можно любоваться!
А что, если ну никак не приходят в голову идеи аппликации, и листики похожи только на листики, а никак не на заек и лисичек? Тогда воспользуйтесь нашими идеями.
Идеи поделок из листьев
Аппликации с животными
Сова из листьев:
Бабочка:
Ёжик:
Белочки:
Рыбка:
Рыжая кошечка
Слон:
Олень:
Павлин:
Птичка с птенцами:
Петух:
И даже орел:
Пейзажи из листьев
Для пейзажа фон можно раскрасить акварелью.
Натюрморты
Портреты
Готовую аппликацию (если она не объемная) можно положить под пресс, чтобы после высыхания она оставалась ровной. Хранить с сухом месте, можно в рамке под стеклом.
Поделки из осенних листьев для детей (50 фото)
Фото: ddtoao.ru
Яркие разноцветные листья – главный повод любить осень. Они красивы сами по себе, и из них получаются роскошные букеты. А еще – интересные творческие эксперименты, поэтому держи подборку легких идей поделок из осенних листьев для детей!
1. Ежик из листьев
Такая поделка понравится самым маленьким. Нарисуй ребенку контур ежика, и пускай он его закрасит и выложит иголочки из листьев.
Фото: detkisovet.ru
2. Декоративная подставка из листьев
А это уже эксперимент для детей постарше. Понадобится воздушный шар, клей ПВА и широкая кисть. Нужно оклеить шар шариками, чтобы получить своеобразную мисочку, а когда она просохнет – аккуратно лопнуть и достать основу.
Фото: wptmp.ru
3. Цветы из осенних листьев
Для таких забавных цветов нужна еще цветная бумага и фломастеры. Нужно вырезать два круга, приклеить глаза и дорисовать рожицу. Сухие листья вкладываются и вклеиваются между половинками вместе со шпажкой или проволокой-ножкой.
Фото: hochupodarit.ru
Зимние поделки в детский садик своими руками (50 фото)
4. Розы из листьев
Из крупных кленовых листьев получаются восхитительные розы в технике, которая напоминает оригами. Сначала скрути плотной спиралью один лист и продолжай оборачивать его следующими, придавая объем.
Фото: znatprovse.ru
5. Осенний венок
Чтобы сделать красивый декоративный венок, нужна основа из пялец, лозы или чего угодно. Листья можно вплетать в нее, как в настоящий венок, или крепить клеем и лентами.
Фото: tojenapad.dobrenoviny.sk
6. Аппликация из листьев
Измельчи в крошку красивые разноцветные листья и используй их, чтобы заполнить отдельные части рисунка. Так они будут не только цветными, но и фактурными. Подойдет обычный клей ПВА.
Так они будут не только цветными, но и фактурными. Подойдет обычный клей ПВА.
Фото: vplate.ru
Поделки из бумаги для детей: 8 простых и красивых идей
7. Трафареты из листьев
Очень красивые рисунки получаются, если положить лист на бумагу и аккуратно пройтись по нему губкой, смоченной в краске. Главное – легко похлопывать, но не давить и не тереть.
Фото: vk.com
8. Льдинки с листьями
В формочки для льда можно вложить маленькие листочки, ягоды и другой декор и залить водой. Если сразу вставить петельки, то потом такие нарядные льдинки подойдут для уличного декора.
Фото: goodhouse.ru
9. Корона из осенних листьев
Основание короны вырежи из плотной цветной бумаги. А потом уже оклей ее красивыми листьями и укрась другим декором – юная принцесса будет в восторге.
Фото: td-viktor.ru
10 идей, как сделать лэпбук своими руками
10. Портреты из листьев
Сначала нужно нарисовать основные очертания лица, и уже потом – раскрасить. Интереснее смотрится, если нос будет объемным из полосочки бумаги. А из сухих листьев выложи волосы и украшения.
Интереснее смотрится, если нос будет объемным из полосочки бумаги. А из сухих листьев выложи волосы и украшения.
Фото: risunok-les.ru
Поделки из осенних листьев для детей – фото и идеи
На самом деле с таким удобным, разнообразным и красочным материалом нет никаких ограничений. Нужно только побольше фантазии и вдохновения. Взгляни!
Фото: biohimist.ru
Фото: .
Фото: pinterest.ru
Фото: ectrl.ru
Фото: retete-usoare.info
Фото: bestlj.ru
Фото: infourok.ru
Фото: mycrafts.ru
Фото: biohimist.ru
Фото: vidtube.ru
Фото: culture.ru
Фото: youtube.com
Фото: .
Фото: larecmasterici.ru
Фото: ok.ru
Фото: fotostrana.ru
Фото: sanmarco1.ru
Фото: pinterest.ru
Фото: stroyblok56.ru
Фото: ectrl.ru
Фото: nl.pinterest.com
Фото: ectrl.ru
Понравилась публикация? Подпишись на наш канал в Яндекс.Дзен, это очень помогает нам в развитии!
Поделки из листьев — 75 лучших фото идей
Осенние листья могут послужить прекрасным украшением вашего дома. Собрав букет кленовых листьев, можно поставить их в вазу, либо сделать своими руками красивую композицию.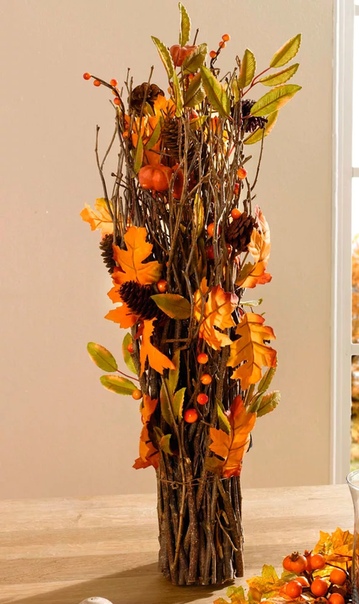 Это не потребует от вас долгих часов кропотливой работы, зато на протяжении длительного времени поделка будет радовать своей красотой и наполнять вас гордостью за проделанный труд.
Это не потребует от вас долгих часов кропотливой работы, зато на протяжении длительного времени поделка будет радовать своей красотой и наполнять вас гордостью за проделанный труд.
Оглавление статьи:
Гирлянды и подвески
Чтобы сделать симпатичную подвеску вам потребуется 2-3 кленовых листа, желательно различных размеров. Покрытые бесцветным лаком листья, окуните в разогретый на водяной бане воск. Далее соедините листья ниткой, не забыв оставить петлю необходимую для подвешивания подвески на стену.
По сходному принципу делается гирлянда, форма и место расположение которой, полностью зависит от вашей фантазии(подставка для вазы, дополнительное украшение комнатных растений). Если объединить несколько гирлянд, получится необычная занавеска.
Венки из кленовых листьев
Одна из самых популярных поделок своими руками. Собирается венок таким же способом, как и венок из одуванчиков или ромашек. Для плетения берется не один, а несколько листочков, в итоге вы получите объёмный и восхитительный веночек. Листочки желательно использовать с удлиненным стебельком. Готовую композицию можно разнообразить еловыми шишками, яркими лентами, веточками и многим другим.
Листочки желательно использовать с удлиненным стебельком. Готовую композицию можно разнообразить еловыми шишками, яркими лентами, веточками и многим другим.
Декорация интерьера — канделябры и свечи
Для изготовления необычного светильника, нужно высушенные кленовые листья, приклеить на любую стеклянную банку. Затем покрыть их бесцветным лаком, а во внутрь банки поместить свечу. Ещё один вариант, обклеить листьями непосредственно саму свечу(используются только толстые свечи), со стороны это будет смотреться как настоящее произведение искусства.
Розочки и букеты из кленовых листьев
Делаются розы из листьев просто, для этого нужно согнуть кленовый лист пополам и свернуть его трубочкой, и так повторяем пока не сформируем розочку, готовый бутон закрепляем на проволоку.
Из готовых роз складываются букеты, плетутся венки, также ими можно украсить всевозможные изделия, вязаные из жестких прутьев. Чтоб придать розам оригинальный вид, на них наносят серебряную либо золотую краску.
Дерево счастья из кленовых листьев
Ещё одна экстравагантная композиция из листьев клена — Дерево счастья. Чтобы соорудить данную поделку, необходимо зафиксировать деревянную тростинку внутри цветочного горшочка по вертикали, поверх тростинки закрепите сферу из поролона. Равномерно распределите листья по сфере не нарушая её изначальной формы. Дополните готовое дерево, бисером вдетым на проволоку вставив его в шар. Цветочный горшочек наполните песком, и украсьте бисером. Существует легенда что сделанный своими руками топиарий приносит удачу.
Домашние композиции
Вырезав в свежем листе крылья бабочки, уберите его под пресс. После высыхания, у вас получится один из элементов для создания необыкновенной домашней композиции. Использовать такие листочки можно для декорирования фото рамочки, для этого просто наклейте и покройте их бесцветным лаком. Вплетая в косички вы получите неповторимую, эффектную прическу.
Создать индивидуальный стиль вашего дома, поможет сделанная своими руками причудливая тарелка с листьями клена.
Получить такую тарелочку, можно обернув пищевой пленкой, обычную порционную тарелку и прилепив к ней в несколько слоёв обильно смазанных клеем листочков.
 Получить такую тарелочку, можно обернув пищевой пленкой, обычную порционную тарелку и прилепив к ней в несколько слоёв обильно смазанных клеем листочков.
Получить такую тарелочку, можно обернув пищевой пленкой, обычную порционную тарелку и прилепив к ней в несколько слоёв обильно смазанных клеем листочков.За тем через определенный промежуток времени, полностью высохшие листья отделяют от тарелки и наносят бесцветный лак. Продев яркую ленточку тарелочку можно повесить на стену.
75 фото
Легкие детские поделки из осенних листьев
Просмотров 4.2к. Обновлено
Детские поделки из осенних листьев просты в исполнении и доступны. Ведь это самый распространенный и легкий в работе осенних материал. Листья разнообразны и привлекательны изначально: разного размера, формы, цвета.
Выполнять детские поделки из осенних листьев для школы, садика, в подарок бабушкам и дедушкам или для собственного удовольствия увлекательно и нетрудно.
Простые детские поделки из осенних листьев
Вот несколько идей для поделок из листьев, с которым справятся даже младшие дети в детском саду.
Сова из осенних листьев
Из осенних листьев легко сделать любую зверюшку самыми различными способами: коллаж, аппликация, конструирование, скручивание и т.д. Предлагаю самый простой способ. Эта сова из осенних листьев может быть выполнена даже самыми маленькими детьми.
Вам понадобится:
- осенние листья,
- прозрачные плотные пакеты,
- глазки — лучше выпуклые объемные,
- самоклеящаяся цветная бумага для клюва,
- маленькие резинки,
- оранжевый картон,
- скотч.

Соберите побольше осенних листьев и поместите их в пакеты. Большой плюс, что для этой поделки из осенних листьев можно использовать даже сухие хрупкие листы, которые не годятся для других поделок.
Закройте пакеты двумя резинками, чтобы сформировать уши. Приклейте глаза, клюв. Достаточно крупные для устойчивости лапы прикрепите скотчем.
Источник фото здесь
Венок из осенних листьев
Для этой поделки нужно выбирать самые красивые и не хрупкие листья. Также вам понадобится:
- картонная тарелка,
- лента или веревочка для петельки-вешалки,
- клей,
- папиросная бумага, тканевые листочки, кисточки, помпоны, блестки, цветная бумага, фольга — по желанию, для украшения.
Для венка нужно вырезать середину из картонной тарелки. И приклеить листики на картон! Это не сложно, и вы можете применить этот принцип ко многим другим природным материалам: полевые цветы летом, ветки зимой…
Ажурный контур листочка
Перенести красивые контуры листа дерева на бумагу можно не только с помощью красок и мелков. Оригинальный и красивый способ — отверстия.
Оригинальный и красивый способ — отверстия.
Если у вас дома нет шила, пробивать отверстия можно канцелярскими кнопками, зубочистками и т.д.
Кроме того, вам понадобится:
- лист белой или цветной бумаги,
- листья деревьев,
- изолента или малярный скотч,
- картон или войлочный коврик для подложки.
Закрепите лист дерева на бумажной основе. И приступайте к перфорации!
Корона из осенних листьев
Вам просто понадобятся листья деревьев! Выберите чистые, достаточно большие листья всех возможных цветов.
Группируем листы одинакового размера. На корону уходит от 12 до 20 кленовых листов в зависимости от их размера. Листья также должны иметь довольно длинный стебель (не менее 5 см).
Сначала отщипните стебель с листа. Сложите первый лист примерно на 1/4 и проделайте то же самое со вторым листом. Помещаем один из двух листов в другой. Затем берем стебель и пришиваем им листочки. Поскольку листья свежие, они не рвутся.
Если вы выполняете такую поделку из осенних листьев дома, то можно упростить процесс, воспользовавшись степлером.
Фигурки из листьев
Штамповать красивые цветные листья фигурным дыроколом — отличная идея. И сам лист, и полученная фигурка становятся уникальным арт-объектом или материалом для создания коллажа.
Идеи поделок из листьев
Поделки из осенних листьев — Nils Blog
«Унылая пора! Очей очарованье! Приятна мне твоя прощальная краса…». Так отзывался об этом периоде Александр Сергеевич Пушкин, ведь осень была его любимым временем года. В отличии же от великого поэта, многие из нас ассоциируют осень с депрессией, плохим настроением, дождями, но на осень можно и нужно посмотреть с другой стороны. В этот период природа наряжается в яркий неповторимый наряд, который состоит из красных, оранжевых и жёлтых листьев, алых рябиновых ягод. Длительные прогулки в парках приносят море позитивных эмоций, ведь можно набрать красивых листьев, а дома сделать удивительные поделки, которые останутся на память о прекрасных осенних деньках.
Какие поделки из осенних листьев можно сделать?
Именно осенью открываются огромные возможности для творчества. Из осенних листьев можно делать аппликации, гербарии, букеты, венки, икебаны и многое другое. Стоит ребёнку рассказать, как можно использовать листья, как он будет с удовольствием делать поделки и украшать ими дом. Для того чтобы сделать красивую поделку понадобятся осенние листья и немного фантазии. Далее читайте подробнее о вариантах творческих осенних работ.
Гербарий
Чтобы сделать гербарий с детьми необходимо собрать красивые осенние листья и высушить их по определённой схеме.
Вам понадобятся:
1. Газетная бумага.
2. Гербарный пресс или лист картона A4.
3. Альбом для засушенных растений.
Как сделать:
1. Соберите красивые опавшие листья, обращайте внимание, чтобы они были плотные и не были слишком сухими.
2. Каждый листок нужно аккуратно расправить на газетной бумаге. Отправляйте стопкой все подготовленные экземпляры, переложенные газетой, под пресс. Если нет пресса, то можно использовать самодельную гербарную папку. Для этого плотно свяжите 2 листа картона форматом А4, проделав отверстия по краям и перевязав шнурком. Сушить листья нужно 2 дня.
Если нет пресса, то можно использовать самодельную гербарную папку. Для этого плотно свяжите 2 листа картона форматом А4, проделав отверстия по краям и перевязав шнурком. Сушить листья нужно 2 дня.
3. Высохшие листья очень хрупкие, поэтому аккуратно извлеките их из-под пресса.
4. Разложить каждый экземпляр листьев можно в специальном альбоме или книге, подписав каждое растение. Храните в сухом помещении.
Букет
Ещё одним прекрасным вариантов поделок из осенних листьев станут букеты. Такой букет украсит интерьер вашего дома, ведь сделанные вещи своими руками и руками ребёнка, особенно приятны и дороги. Из обычных кленовых листьев можно сделать вот такие вот розы, подключайтесь всей семьёй к этому увлекательному занятию и начинайте творить красоту!
Вам понадобятся:
1. Листья клёна со стебельками.
2. Нитки.
Как сделать:
1. Листик согните пополам, чтобы глянцевая сторона оказалось с внешней стороны.
2. Скрутите его так, чтобы получилась трубочка.
3. Возьмите другой лист и повторите действия из 1 пункта. Затем снова заверните его в трубочку.
4. Чтобы бутоны получались пышными используйте больше листьев.
5. Основание скрепите ниткой, плотно обмотайте низ каждой «розочки».
6. Соедините получившиеся цветы в букет.
Осенний декоративный венок
Такой венок украсит ваш дом или квартиру. Для его изготовления можно использовать не только осенние листья, но и ягоды, шишки и даже фрукты, например, засушенный гранат. Это замечательное украшение будет радовать всю семью и напоминать вам о приходе яркой и красочной осени.
Вам понадобятся:
1. Веточки и листья любого дерева.
2. Шишки и ягоды.
3. Клеевой пистолет.
4. Ножницы.
5. Бечёвка.
6. Золотые нитки.
7. Любой понравившийся декор, который можно прикрепить к венку.
Как сделать:
1. При помощи веточек сформируйте конструкцию овальной формы и скрепите её с помощью бечёвки.
2. Обмотайте венок золотой ниткой.
3. Привяжите ягоды и шишки к венку.
4. Прикрепите декор с помощью ниток и клея.
Аппликация
Самым маленьким детишкам будет интересно сделать аппликацию из осенних листьев. Это может быть любой пейзаж или изображение забавных зверьков. Ребёнок может выбрать любую тему и положиться на свою фантазию. Получившуюся картинку из осенних листьев можно повесить на видное место и любоваться всей семьей.
Вам понадобятся:
1. Всевозможные цветные листья.
2. Цветная бумага.
3. Веточки.
4. Картонная бумага.
5. Грозди высушенной рябины.
6. Клей ПВА.
Как сделать:
1. Высушите собранные листья.
2. Прорисуйте на картонной бумаге контур того, что вы хотите изобразить.
3. Наклеивайте листья, создавая форму своему персонажу.
4. Приклеивайте веточки и украшайте картинку рябиной и веточками.
Икебана из засушенных листьев и цветов
Такая поделка – это своеобразный букет из осенних листьев, ягод и овощей. Используйте всё, что нравится и ваша поделка будет настоящим произведением искусства!
Используйте всё, что нравится и ваша поделка будет настоящим произведением искусства!
Вам понадобятся:
1. Листья и веточки.
2. Овощи и фрукты.
3. Засушенные цветы.
4. Декоративные элементы.
5. Клеевой пистолет или клей ПВА.
6. Тыква.
Как сделать:
1. Соберите сухие листья, ягоды рябины, подготовьте овощи или фрукты, которые хотите использовать. Подойдут, например, маленькие патиссоны, морковь, гранат или яблоки.
2. Разрежьте большую тыкву пополам. Из нижней части вытащите мякоть. Она будет служить вазой. Верхнюю часть тыквы отложите.
3. Теперь можно собирать букет. Используйте много элементов, так ваш букет будет пышным и ярким. Прикрепляйте к веточкам с помощью клея декоративные элементы, также можно прикрепить фрукты и овощи. Вставляйте в букет засушенные цветы и грозди ягод.
Как видите, из осенних даров природы можно сделать разнообразные поделки, которые впечатлят своей креативностью и яркостью. Наполните свой дом позитивными эмоциями, создавая своими руками и руками ребёнка настоящие произведения искусства!
КАРТИНЫ из листьев.
 10 разных техник + много фото.
10 разных техник + много фото.
Добрый день. Сегодня мы будем делать самые разные картины из листьев и сухих цветов. Здесь речь пойдет не о детских аппликациях. Мы будем делать ВЗРОСЛЫЕ шедевры – для декора интерьера. Хотя детские работы тут тоже будут, увидите.
Итак, как своими руками сделать картины из сухих или сочных листьев, из цветов и трав.
Вот вам РАЗНЫЕ способы… и РАЗНЫЕ техники поделок из листьев в виде картин.
И каждая поделка-картина– под силу даже начинающему мастер-ломастеру.
Ай-да, нырнем в творческий порыв.
Объемная картина из СУХИХ ЛИСТЬЕВ И ЖЕЛУДЕЙ
(суть работы — своими руками)
Начнем с яркого художественного «полотна» — осенняя композиция из листьев и желудей…
Суть работы – Берем лист фанеры – и листья наклеиваются в нахлест друг на дружку… Края фанерного листа оставляем чистыми – туда будем набивать нашу рамку.
Картина из сухих листьев получается объемная, поэтому мы ее под стекло помещать не будем. И рамка идет отдельно без стекла (просто рама из деревянных реек… и просто кусок фанеры (или двп) в размер к этой рамочке.) А далее выбираем способ на ваш вкус – с акриловым лаком, или с парафином от свечей. В такой картине могут участвовать даже маленькие дети. Эту идею можно реализовать в кружках творчества.
Способ с акриловым лаком. Покупаем в магазине акриловый лак для поделок. Наклеили листья на холсты… нанесли слой лака дали высохнуть… снова нанесли слой… снова высушили… и еще слой… и т.д. пока не заблестит так, как вам хочется.
Способ с парафином. Растопили свечи в кастрюле. Обмакнули каждый лист и положили на холст. Они сами будут приклеиваться друг к дружке парафином. Очень быстрый и спокойный способ сделать осеннюю блестящую картину из листьев. Листья запечатанные в парафине могут годами не терять сочность формы и цвета.
Вы можете выложить такие картины, укладывая листья в хаотичном порядке. А можете придумать определенный узор. Гармонию плавного перехода цвета.
А также вы можете постараться и сделать круговые симметричные узоры из листьев разного размера и цвета. Они называются мандалы. Еще какие-то древние народы придумали такие центрические узоры, и считается что они обладают магией гармонии и красоты. На мандалы приятно смотреть. В нашем случае магия наших мандал будет сделана из светлого и чистого материала: природной листвы – поэтому такие центрические картины будут нести только лечить и успокаивать, как сама природа.
Тут конечно проведена кропотливая работа – нужно чтобы размеры листиков были одинаковы в каждом из кругов. И чтобы каждый круговой ряд отличался друг от друга по размеру и форме своего повторяющегося элемента.
Такие картины из листьев и сухих трав можно делать именно ПОД ЦВЕТ вашего интерьера.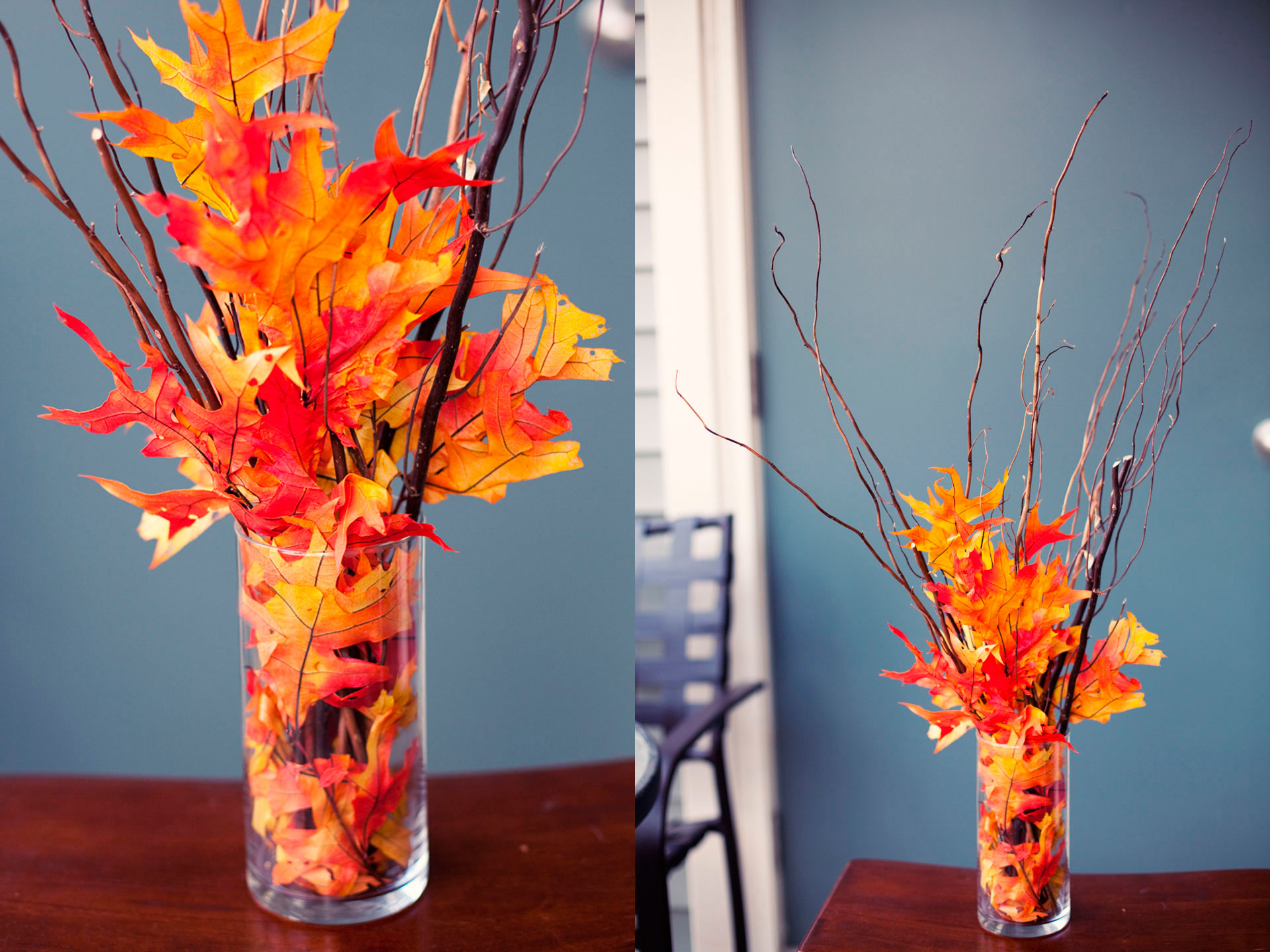 Чтобы идеально вписывалась картина в помещение.
Чтобы идеально вписывалась картина в помещение.
В ярких оранжевых тонах – к оранжево-желтому интерьеру.
Или к интерьеру в темных шоколадно-приглушенных тонах… другая копозиция из осенних листьев подойдет.
Ну а теперь еще одна шикарная идея…
Картины из ПАРЯЩИХ листьев.
Вот смотрите на фото ниже. Нравится? Мне тоже )). Хотите сделать сами – точно так? Тогда читайте дальше.
Если листья засушить – не зажимая из между страницами книги – а просто положить в плоскую коробочку (например из-под конфет)и засыпать манной крупой… то получится вот что…
Крупа прижмет листик ровно настолько, чтобы не дать ему скрючиться при высыхании – и тогда лист высохнет, сохранив свою гладкую изящную форму.
Такие листья можно закрепить за стеклом в рамочку… и они будут красивыми и ровными внутри картины.
Вы скажете… «Ага… а ведь тут на фото видно что листья не зажаты рамкой… а как бы парят внутри рамки. Как это сделать?
Как это сделать?
Очень просто. Нам нужна рамочка – с пустотой внутри (поискать в продаже или сделать самим…
Для того чтобы сделать такую глубокую воздушную рамку-коробку нам надо… взять обычную рамку со стеклом (реечки и остекленение)… тонкий лист фанеры (или двп)… и четыре отрезка брусика (толстенькой реечки… чем толще реечка-брус, тем больше будет пространство внутри рамки)…
И вот, собрав все нужное, создаем конструкцию такой рамки-коробочки…
На лист фанеры набиваем брусики – т.е. создаем борта… и на эти борта – сверху крепим нашу верхнюю остеленную раму. И в итого получаем рамку с воздухом внутри – рамку-коробочку.
Теперь дальше…
Как заставить лист «парить» внутри рамки-коробки…
Во-первых, создаем фон – наше фанерное дно рамки …либо ОКРАШИВАЕМ в белый цвет… либо ОКЛЕИВАЕМ белой бумагой.
По центру прикладываем листики… и прикидываем взглядом, где у этого листика самое центральное место. Помечаем это место карандашиком на дне рамки.
Помечаем это место карандашиком на дне рамки.
Далее к помеченному месту приклеиваем кусочек пенопласта (или толстеньки обрезок деревянной реечки) – то есть создаем «пенек-возвышенность» на дне рамки.
Вот к этому пеньку (пенопластовому, или деревянному) мы приклеем наш листок. И получится, что он как бы завис в воздухе и не касается стены своей рамки.
А еще можно круче сделать…
Можно с рамке создать иллюзию листа, лежащего НА ПЕСКЕ… Вот как это сделать…
До того, как приклеивать наш лист к «пеньку» мы можем сделать ПЕСЧАНЫЙ ФОН на дне рамки. Для этого берем клеевой пистолет … и наносим неровный слой клея на дно рамки… где-то гуще, где-то меньше… И пока клей не засох насыпаем на него мелкий речной песочек. Даем засохнусть и после высыхания вытряхиваем из рамки лишний песок. Смотрим, и если остались незапесоченные места… смазываем эти лысые места еще раз клеем и снова посыпаем песком.
Если нет клеевого пистолета (кстати его можно купить в любом строительном магазине за 7 долларов)… то можно использовать обычный клей пва – тоже погуще слой нанести и песочком пропесочить… но сушить дольше придется… и песок лучше мелкий брать,крупнозернистый гравий клей пва держать не будет.
В итоге у вас получатся красивые картины – как будто листья лежат на песке…
А еще в такие рамочки вы можете помещать не просто ЧИСТЫЕ осенние листья – а расписные, с нарисованной на них картиной.
ЛИСТЬЯ-КАРТИНЫ
технике росписи листа.
Можно выкладывать листьями картины, а можно рисовать картины на самих листьях. Краской – маслом или гуашью.
Если работаете гуашью, то после завершения рисунка нужно такую картину побрызгать лаком для волос (чтобы закрепить краску и придать ей более сочную яркость, как на фото ниже).
Такие оригинальные картины на листьях можно дарить родным и друзьям, приурочить их даже к Новому Году можно.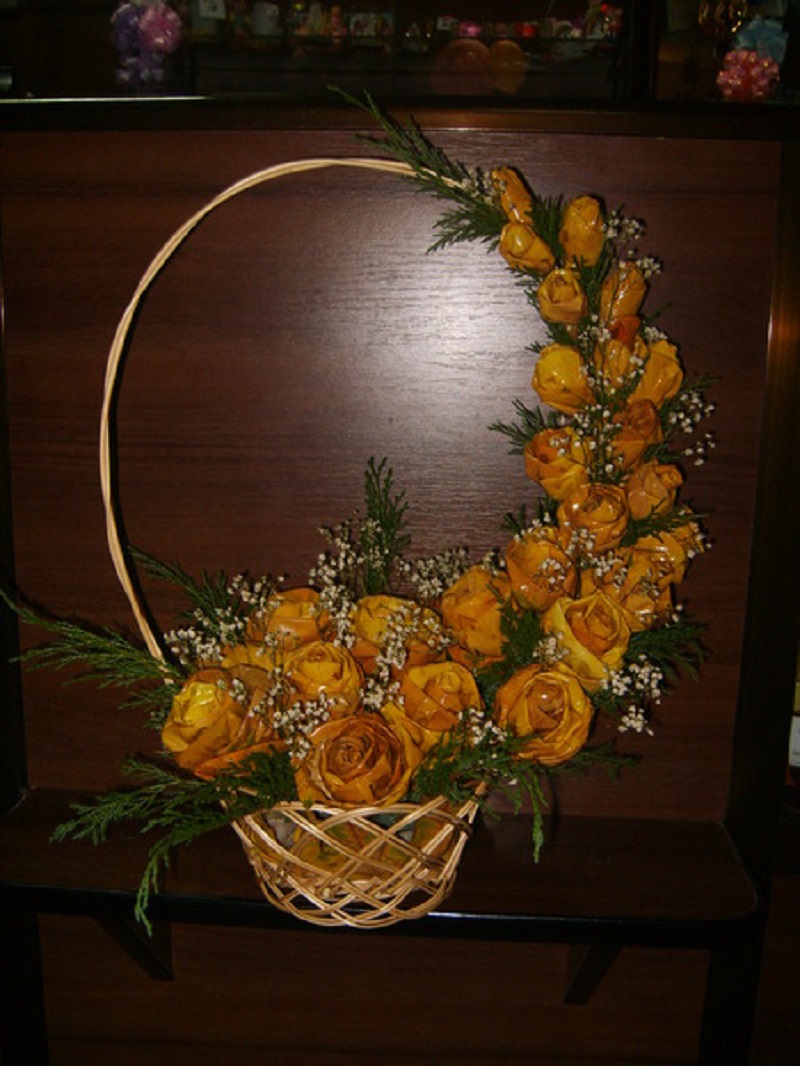
А чтобы картина –подарок из осеннего листа долго сохранилась – не высохла, не сжалась, не скрючилась, надо ее запечатать в парафине (или воске). Для этого растапливаем свечи в мисочке и за хвостик окунаем листья в парафин. Вынимаем и сушим, подвесив за хвостик на нитках.
А если вы не художник, то вы можете рисовать простые графические узоры – обычная симметрия геометрических повторяющихся фигур.
Простой мастер-класс
по рисункам на листьях.
И знаете что, я пожалуй сейчас вас влюблю в идею картин на осенних листьев. Я дам вам инструкции, вмести с которыми придет понимание, и за компанию придут интерес, желание и любовь.
Начнем с самых простых поделок-картин на листьях. Вот например, таких силуэтных рисунках… В них есть только ФОН и только ТЕМНЫЙ СИЛУЭТ. Фон – это просто. И силуэт – это просто. Поэтому и начнем с таких простых художественных задач, чтобы не отпугнуть вас, а заманить.
Находим в интернете красивую картинку. Например вот такую. Распечатываем ее в киоске фото-печати (не думаю, что у вас дома есть цветной принтер).
На чистом листе бумаги обводим карандашом кленовый лист, вырезаем обведенный силуэт – получаем трафарет с дыркой в форме кленового листа. И этой кленовой дыркой прикладываем бумажный трафарет к нашей картинку в понравившемся месте. Например вот так.
И теперь можно перерисовывать рисунок с этого бумажного образца на кленовый лист. Сначала фон – небо и воду, потом черный силуэт дельфина. Можно для дельфина сделать тоже дырявый трафарет из бумаги –положить на фон и красить его черной краской.
По такому принципу можно сделать любые эпизоды с любых картин. Хоть с Моно Лизы. Эффектно смотрятся элементы с глазами – хищный взгляд птицы, или загадочный взгляд женщины.
Очень красиво смотрятся ТОЧЕЧНЫЕ РИСУНКИ, нарисованные ватной палочкой. Тут тоже сначала делаем фон. Сушим его. А потом наносим точками рисунок. Самый простой для начала. Например силуэт Эйфелевой башни.
Тут тоже сначала делаем фон. Сушим его. А потом наносим точками рисунок. Самый простой для начала. Например силуэт Эйфелевой башни.
Очень интересно смотрятся картины на листьях с ПЛАВНЫМ ПЕРЕХОДОМ ЦВЕТА. Градиентным переливом оттенков краски (как на картинке ниже). Вот как создать в домашних условиях такой нежный фон на вашей картине…
Чтобы сделать фон на листике с эффектом ПЛАВНОГО ПЕРЕЛИВА одного оттенка в другой нужно использовать не кисть, а поролоновую губку с мелкими порами.
- На губку наносим широкие полосы краски – желтую, желто-оранжевую смешанную, оранжевую.
- Отпечатываем губку на лист.
- Первый отпечаток будет бледным, поэтому мы повторно наносим полосы краски и несколько раз повторяем эту процедуру, пока фон не станет нужной насыщенности.
Потом тонкой кисточкой наносим черные контуры силуэта (например птички), и закрашиваем контуры. Из бумаги можно вырезать силуэт птички и его обвести. Или вырезать трафарет-дырку птички – положит на лист и закрасить.
Или вырезать трафарет-дырку птички – положит на лист и закрасить.
Вы можете рисовать любые вещи на кленовых листьях, самые простейшие и самые сложные. Цитрусовые дольки или иллюстрацию из сказки Маленький Принц.
Идем далее…
Картины ОТПЕЧАТКИ
из окрашенных листьев.
Дети, часто на занятиях в школе или в детском саду делают отпечаки осенних листьев. Мелом или красками.
В технике с меловым отпечатком, мы кладем белую бумагу поверх осеннего листа – и заштриховываем все это мелом – от штриховки все шероховатости листа проступают на бумагу.
А в технике с краской – на осенний лист спонжиком (лучше, чем просто кисточкой) наносим краску и, пока она не высохла, быстро припечатываем лист окрашенной стороной к бумаге.
И очень интересно получается, когда мы делаем не оранжевый лист, на белой бумаге, а НАОБОРОТ, сначала закрашиваем бумагу в оранжевый цвет гуашью, а потом белой краской покрываем лист и создаем белый отпечаток листа на оранжевом фоне. Получается гораздо интереснее и насыщеннее по цвету. Согласитесь?
Получается гораздо интереснее и насыщеннее по цвету. Согласитесь?
Такие отпечатки из листьев можно сколлажировать в интересную картину.
Вот как на фото ниже – картина была изначально поделена на зоны… для каждой зоны выбран свой фон из брызг (как делать фон из брызг в этой же статье я скажу ниже)…
И потом в каждую зону прикладывается свой лист-штамп. Получается авторское произведение искусства
А можно сделать еще красивее… если наносить отпечаток осеннего листа не на чистый белый лист, а на подготовленный. Заранее наносим на лист опечатки мыльных цветных пузырей… и потом когда отпечатки высохнут… на этот пузырчатый фон нанести отпечатки листьев. Это достаточно просто – обычный мыльный раствор разливаем по баночкам, добавляем гуашь цветную – и трубочкой для коктейля надуваем пузырь и, когда он уже большой, наклоняем его к бумаге, чтобы он об нее лопнул.
И будет ощущение КАК БУДТО эти листья плавают в лужах во время дождя… видели когда нибудь как дождь вздымает пузыри на лужах и в этом пузырчатой луже плавают листья… Вот такая картина из листев и дождевых брыг… станет настоящим украшением вашей комнаты…
Картины из листьев
обратные отпечатки.

«Обратные отпечатки» — это название которое я придумала для техники, которая на выходе дает вот такой результат — трафаретной техники. (фото ниже).
Техника трафаретов простая – очень простая. Вот смотрите…
- Берем белый лист бумаги… кладем на него лист, стебель травы, или веточку.
- Кладем данный лист внутрь большой коробки (чем-больше тем лучше) сейчас поймете, зачем…
- Берем в руку балончик с цветной краской – и брызгаем поверх бумаги с лежащим на ней листом\стебельком\цветком. (Так как вся наша работа ведется внутри коробки – брызги не разлетаются по комнате и не пачкают мебель).
В результате – весь лист окрашивается в сочный цвет.. . а то место где была веточка остается назакрашенным.
И так как брызги из баллончика вылетают под разным углом наклона – мы имеем не четкие контуры растения… а как-бы размытую тень листа… что только добавляет нашей картине из листьев художественной выразительности.
Или можно использовать брызгалку попроще, из зубной щетки.
Использовать обычную акварель или гуашь, а разбрызгивателем послужит обычная зубная щетка.
Картины штампы – из сочных листьев.
А можно оставить на бумаге отпечаток листа – совсем топорным способом. Вернее «молотковым»
Берем бумагу – кладем лист (сочный зеленый, желтый, красный) – накрываем салфеткой бумажной –и поверх салфетки стучим-колотим молотком по листику. В результате сок и пигмент с листа перепечатываются на бумагу.
Можно каждый лист отпечатывать отдельно… подкладывая листик за листиком… поэтапно придумывая сюжет композиции.
А можно – сразу разложить всю листовую и цветочную композицию – на нашей будущей картине — накрыть салфеткой и молотить самозабвенно – до полного растерзания растений.
Чтобы их яркие души остались запечатленными на веки — на вашем нетленном полотне.
ПЛОСКАЯ картина
из сухих трав, листьев и цветов.
Ну и конечно – стандратный вариант картины из природных материалов. Когда травы, листья и цветы засушиваются в плоском виде между страницами книг. И в такой прессованной форме выкладываются на картины.
Еще больше таких ПЛОСКИХ картин из цветов вы найдете в моей статье «Аппликации-КАРТИНЫ из сухих цветов (42 фото)».
ЛУЧШИЙ СПОСОБ СУШИТЬ листья и травы
(чтобы книги не портить).
Лист с двух сторон оборачиваем бумажной салфеткой, потом плотной бумагой, потом пеленкой хлопковой и гладим утюгом.
Утюг должен быть не очень горячим (иначе лист почернеет). Чуть чуть прогладили, чуть чуть он нагрелся как на летнем солнце. Оставил некоторую влагу в салфетке. Потом поменяли салфетку на сухую – повторили.
И после этого можно тоже в бумажной салфетке положить между тяжелыми книгами.
Картины маркером с листьями
(простая графика).
Вы можете просто черным маркером нарисовать любую картину – а листья будут играть лишь роль отдельных элементов, внесенных в вашу графику.
Картины из листьев
В мозаичной технике.
Мозаичная техника – самая красивая, на мой взгляд. Очень нежно, воздушно, настоящее кружево из природных материалом. И так приятно выкладывать кусочек за кусочком – нежно, точно, добиваясь правильного сходства.
Сначала сложить все на сухую бумагу – потом сфотографировать конечный вариант. Убрать все с листа – бережно переложив каждый элемент в коробку. И потом уже с клеем в руках выкладывать мозаику-картину, сверяясь с фото-образцом.
За основу нужно брать лист бумаги с переведенным на него силутом животного. Положить листь бумаги на экран компьютера с картинкой и слабой линией карандаша перевести контуры животного. А потом потихоньку заполнять все это пространство кусочками листьев.
А потом потихоньку заполнять все это пространство кусочками листьев.
Олень, сова – достаточно сложные работы. Самая ваша первая работа должна быть простая, чтобы не отбить охоту. Самое простое – это симметричное животное. Одинаковое слева и справа. Так вы просто будете начинать от центра – и одновременно справа и слева от него выкладывать одинаковые кусочки растений.
В качестве материала можно использовать сухие листья, или листья запечатанные в парафине (обмакнутые в воск растопленной свечи).
Картины из листьев
В многослойной технике.
Или можно сделать аппликацию из листьев –в объемной технике – когда фактура листа передает фактуру зверька… вот как здесь на картине из листьев с совами – когда фактура и форма листиков передает фактуру и форму перышков.
А еще вы сможете продавать свои работы – вот я нашла очень интересный сайт, где автор продает – не сами поделки – а открытки с изображением этих работ. И не дешево – а по хорошей цене. Отличный пример красивого хобби и бизнеса в одном. https://www.floraforager.com/
И не дешево – а по хорошей цене. Отличный пример красивого хобби и бизнеса в одном. https://www.floraforager.com/
Картины из листьев с птицами
мастер-класс
(на основе детских разукрашек).
Вы можете создать картину, которую нарисуете листьями — как художник мазками кисти. Каждый листок это широкий мазок кисти художника. Для такой картины нужно распечатать на принтере обычную детскую разукрашку с птичкой – в крупный размер.
А потом эту картину разукрасить, но не карандашами, а листьями. Выложить каждый элемент разукрашки листьями определенного цвета. И вы получите эксклюзивную картину из листьев.
В гугле очень много разукрашек с птицами – распечатайте, и попробуйте из сухих осенних листьев сделать из этой обычной детской разукрашки настоящую картину-шедевр. Вы сможете гордиться своей работой.
Вы можете сделать весенние картины из листьев, если засушите целые веточки цветущей вишни. Цветы зажимаются прессом, между бумажными салфетками. Если вы хотите чтобы цветы были объемными, то их можно сулить засыпав сухой манной крупой, или просеяным очень сухим речным песком.
Цветы зажимаются прессом, между бумажными салфетками. Если вы хотите чтобы цветы были объемными, то их можно сулить засыпав сухой манной крупой, или просеяным очень сухим речным песком.
Это достаточно простые аппликации из листьев – для 1 класса школы… Для таких простых аппликаций я напишу отдельную статью… и тогда здесь заработает на нее ссылочка.
Еще больше вариантов аппликаций из осенних листьев вы найдете в моей статье «Осенние аппликации (5 техник + 50 фото).
Идем далее… в прекрасную страну Францию..
Картины ПЕЙЗАЖИ – из сухих листьев и цветов.
Вот какие картины из листьев, лепестков цветов и трав делает одна французская художница… Там ниже вы увидите ее контакты… если вам нравятся такие работы… вы можете связаться с автором, чтобы заказать себе подобный шедевр.
Жалко что нельзя их увеличить, чтобы рассмотреть все в мельчайших подробностях.
Вы тоже можете выкладывать из листьев небольшие пейзажные работы. Которые не требуют столько сил и таких затрат природного материала.
Картины ПОРТРЕТЫ – из сухих листьев.
А вот композиции из осенних листьев, которые складываются в очертания женской головки.
Можно сделать целую галерею картин из листьев в тематике «Женщина-очень». И выставить в своей гостиной на аханье всем гостям.
Картина из листьев
ВЛЮБЛЕННЫЕ.
И завершим мы нашу статья – любовью. С нее все начинается. Пусть с ней все и продолжается.
Двое влюбленных. Картина, которая приятна для глаз в любую эпоху и в любой цивилизации.
Как видите, идей очень много…
Творите. Не ленитесь быть счастливыми. Жизнь дана — не для планов на будущее.
И я обязательно буду искать для вас новые идеи…
Вот прямо сейчас нашла…
УДИВИТЕЛЬНЫЕ картины из листьев — Вьетнамского художника Ле Дык Чунга
Да-да и это все сделано из листиков – присмотритесь… Подробнее по ссылке выше.
А ЕЩЕ…
У меня есть другие статьи по осенним букетам и поделкам из природного осеннего материала…
Осенний БУКЕТ — 50 фото-композиций из листьев и цветов
Осенние композиции своими руками — 28 фото-идей поделок.
Ольга Клишевская, специально для сайта «Семейная Кучка».
Читайте НОВЫЕ статьи на нашем сайте:
на Ваш сайт.
Осенние поделки: аппликации из осенних листьев. Коллаж из осенних листьев
Осень радует своими красками. Желтые, бордовые, оранжевые, коричневые, самых невероятных форм и размеров — осенние листья, кажется, специально созданы для творчества и развития фантазии. Обязательно во время прогулки с ребенком по парку или в лесу соберите коллекцию осенних листьев.
Даже совсем маленьким детям будет интересно играть с ними. Малыши любят мять, рвать листья, рассматривать их, сортировать по форме, цвету, размеру. А с детьми постарше можно изготовить интересные осенние поделки из:
А с детьми постарше можно изготовить интересные осенние поделки из:
— осенних листьев
— шишек
— из желудей
— овощей и фруктов
— каштанов и др.
Поделки из листьев
Очень увлекательное занятие наблюдать, как из обычных листьев, которые валяются у нас под ногами, получаются забавные зверюшки, человечки, пейзажи или абстрактные узоры. Занятия аппликацией способствуют развитию у детей воображения, тонкой моторики, развивают усидчивость. Перед работой собранные листья можно прогладить утюгом, разложив их между двумя листами бумаги.
Из листьев, как из бумаги, можно вырезать ножницами фрагменты будущей картинки, т.е. использовать для аппликации не целиком лист, а только его часть.
При изготовлении осенних аппликаций из листьев недостающие детали изображений можно дорисовать карандашами, фломастерами или красками.
Из листьев, как из бумаги, можно вырезать ножницами фрагменты будущей картинки, т. е. использовать для аппликации не целиком лист, а только его часть.
е. использовать для аппликации не целиком лист, а только его часть.
Если у вас есть фигурный дырокол, то можно с его помощью вырезать красивые картинки из осенних листьев.
Сухие листья разных цветов можно покрошить руками (увлекательное занятие для малышей!), после чего приклеить их на рисунок. Делается это следующим образом: в нужном месте нанесите на картинку слой клея, посыпьте сверху толчеными сухими листьями, дайте клею подсохнуть, после чего стряхните остатки листьев. Красота! Примечание: если листья плохо крошатся, подержите их немного в микроволновке на небольшой мощности.
Большую коллекцию интересных аппликаций из осенних листьев вы найдете у нас в Фотоальбоме.
И напоследок — необычное решение — обклейте бумажные шаблоны (льва, рыбку и ежика) осенними листьями, в результате получились оригинальные осенние аппликации.
Можно играть в интересную игру с использованием осенних листьев. Родителям надо заранее приклеить на листы бумаги половинки листочков, а ребенок должен будет потом дорисовать симметрично вторую половинку листа.
Родителям надо заранее приклеить на листы бумаги половинки листочков, а ребенок должен будет потом дорисовать симметрично вторую половинку листа.
- Коллаж из осенних листьев
Используя прозрачную самоклеющуюся пленку, можно сделать вот такой симпатичный коллаж из осенних листьев. Для этого надо поместить листья между двумя слоями пленки (пленка расположена липкой стороной внутрь). Его можно применять как салфетку для стола, например.
А еще на сухих листьях можно просто рисовать:
Надеемся, что вас заинтересуют осенние поделки из бумаги, желаем вам творческих успехов!
открытый дистрибутив aws elasticsearch
Уведомление : Неопределенный индекс: social_icon_position в /home/mdisario/public_html/huntdaily.com/wp-content/plugins/wp-social-sharing/includes/class-public. php онлайн 30
php онлайн 30
Проект включает OpenSearch (на основе Elasticsearch 7.10.2) и OpenSearch Dashboards (на основе Kibana 7.10.2), а также Open Distro для Elasticsearch, предыдущего дистрибутива Elasticsearch от AWS. Стремясь сохранить код для проекта Elasticsearch незапятнанным проприетарными битами, Amazon Web Services (AWS) в понедельник выпустила нижестоящий дистрибутив под названием Open Distro for Elasticsearch, который, как обещает компания, является «100-процентно открытым исходным кодом» под Apache 2.0 лицензия. Elasticsearch — это распределенная поисковая и аналитическая система с открытым исходным кодом, которая используется крупными … Python Apache-2.0 82 288 8 (требуется помощь по 1 проблеме) 1 Обновлено 30 апреля 2021 г. Обновлено 30 апреля 2021 г. асинхронный поиск Например, вы можете указать my-index-*. Но в мире свободного программного обеспечения с открытым исходным кодом, где незначительные изменения в непонятном языке могут вызвать интернет-эквивалент Столетней войны, выпуск открытого дистрибутива AWS для Elasticsearch вызвал горячие споры. Программное обеспечение с открытым исходным кодом было одной из самых больших историй успеха в индустрии программного обеспечения. Последний залп произошел в этом месяце, когда AWS переименовала разветвленный проект из Open Distro for Elasticsearch в OpenSearch. AWS сотрудничает с Expedia и Netflix, среди прочего, над Open Distro для Elasticsearch, настаивая на том, что это не форк, а «распространение Elasticsearch с добавленной стоимостью, которое на 100% открыто […] Более десяти месяцев назад мы объявили об Open Distro для Elasticsearch. , полностью открытая версия Elasticsearch, популярной поисковой системы на основе Apache Lucene.В ноябре 2020 г. мы объявили о поддержке OpenTelemetry на AWS в дистрибутиве AWS для OpenTelemetry (ADOT) — безопасном, готовом к работе, поддерживаемом AWS дистрибутиве проекта OpenTelemetry Cloud Native Computing Foundation (CNCF). AWS подверглась резкой критике в январе, когда объявила о сервисе Amazon DocumentDB с «совместимостью с MongoDB», которую некоторые наблюдатели раскритиковали… Поделитесь своими отличными идеями и примерами кода с сообществом Open Distro for Elasticsearch.
Программное обеспечение с открытым исходным кодом было одной из самых больших историй успеха в индустрии программного обеспечения. Последний залп произошел в этом месяце, когда AWS переименовала разветвленный проект из Open Distro for Elasticsearch в OpenSearch. AWS сотрудничает с Expedia и Netflix, среди прочего, над Open Distro для Elasticsearch, настаивая на том, что это не форк, а «распространение Elasticsearch с добавленной стоимостью, которое на 100% открыто […] Более десяти месяцев назад мы объявили об Open Distro для Elasticsearch. , полностью открытая версия Elasticsearch, популярной поисковой системы на основе Apache Lucene.В ноябре 2020 г. мы объявили о поддержке OpenTelemetry на AWS в дистрибутиве AWS для OpenTelemetry (ADOT) — безопасном, готовом к работе, поддерживаемом AWS дистрибутиве проекта OpenTelemetry Cloud Native Computing Foundation (CNCF). AWS подверглась резкой критике в январе, когда объявила о сервисе Amazon DocumentDB с «совместимостью с MongoDB», которую некоторые наблюдатели раскритиковали… Поделитесь своими отличными идеями и примерами кода с сообществом Open Distro for Elasticsearch.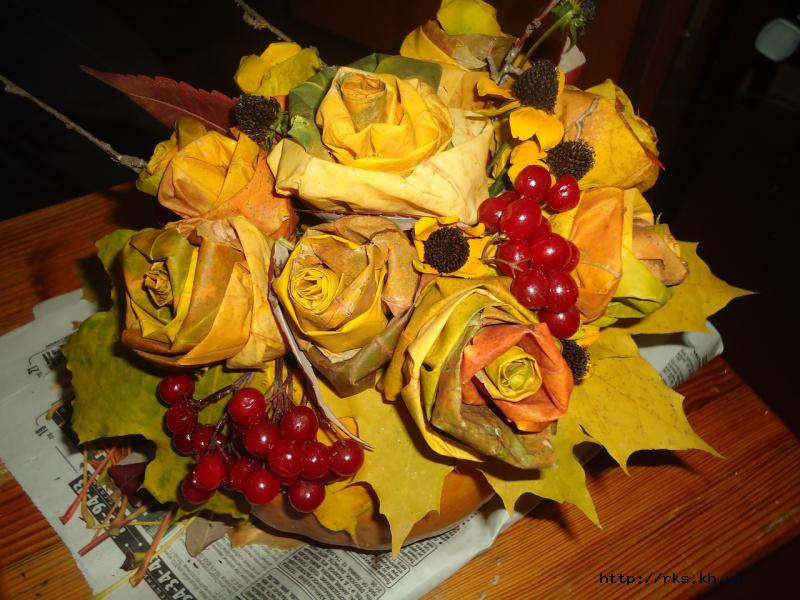 Форк Kibana называется OpenSearch Dashboards.Поэтому мы решили сотрудничать с другими компаниями, такими как Expedia Group и Netflix, для создания нового дистрибутива Elasticsearch с открытым исходным кодом под названием «Открытый дистрибутив для Elasticsearch». Open Distro for Elasticsearch — это дополнительный дистрибутив со 100% открытым исходным кодом, который будет ориентирован на внедрение инноваций с дополнительными функциями, чтобы предоставить пользователям многофункциональный вариант с полностью открытым исходным кодом. AWS поддерживает приверженность обеспечению того, чтобы исходный код Elasticsearch и Kibana оставался открытым. В ноябре 2020 г. мы объявили о поддержке OpenTelemetry на AWS в дистрибутиве AWS для OpenTelemetry (ADOT) — безопасном, готовом к работе, поддерживаемом AWS дистрибутиве проекта OpenTelemetry Cloud Native Computing Foundation (CNCF).С помощью ADOT вы можете настроить приложения для отправки коррелированных метрик и трассировок в несколько решений AWS, таких как наша Amazon Managed Service… Open Distro for Elasticsearch Сегодня мы запускаем Open Distro for Elasticsearch.
Форк Kibana называется OpenSearch Dashboards.Поэтому мы решили сотрудничать с другими компаниями, такими как Expedia Group и Netflix, для создания нового дистрибутива Elasticsearch с открытым исходным кодом под названием «Открытый дистрибутив для Elasticsearch». Open Distro for Elasticsearch — это дополнительный дистрибутив со 100% открытым исходным кодом, который будет ориентирован на внедрение инноваций с дополнительными функциями, чтобы предоставить пользователям многофункциональный вариант с полностью открытым исходным кодом. AWS поддерживает приверженность обеспечению того, чтобы исходный код Elasticsearch и Kibana оставался открытым. В ноябре 2020 г. мы объявили о поддержке OpenTelemetry на AWS в дистрибутиве AWS для OpenTelemetry (ADOT) — безопасном, готовом к работе, поддерживаемом AWS дистрибутиве проекта OpenTelemetry Cloud Native Computing Foundation (CNCF).С помощью ADOT вы можете настроить приложения для отправки коррелированных метрик и трассировок в несколько решений AWS, таких как наша Amazon Managed Service… Open Distro for Elasticsearch Сегодня мы запускаем Open Distro for Elasticsearch. В этом семинаре используется AWS Event Engine. Для разрешений кластера добавьте группу действий cluster_composite_ops_ro. Открытый дистрибутив для Elasticsearch от Amazon AWS Как видно из приведенной выше таблицы, каждая версия поддерживает основные функции механизма поиска и аналитики Elasticsearch — индексирование данных, поиск данных и, наконец, анализ индексированных данных с использованием агрегаций.Что ж, на самом деле этот шаг для Open Distro поместил Elastic в Zugzwang, и они отреагировали открытием X-Pack, однако он по-прежнему не бесплатный и не имеет лицензии с открытым исходным кодом. AWS добавила, что все новые выпуски ее службы Elasticsearch будут основаны на ее форке и что это изменение не «замедлит скорость улучшений» службы. Open Distro for Elasticsearch использует открытый исходный код Elasticsearch… Эта программа использует последние проприетарные дополнения AWS к Elasticsearch и… Создайте новую роль с именем read_only_index.12.03.2019. Откройте дистрибутив для драйвера ODBC Elasticsearch.
В этом семинаре используется AWS Event Engine. Для разрешений кластера добавьте группу действий cluster_composite_ops_ro. Открытый дистрибутив для Elasticsearch от Amazon AWS Как видно из приведенной выше таблицы, каждая версия поддерживает основные функции механизма поиска и аналитики Elasticsearch — индексирование данных, поиск данных и, наконец, анализ индексированных данных с использованием агрегаций.Что ж, на самом деле этот шаг для Open Distro поместил Elastic в Zugzwang, и они отреагировали открытием X-Pack, однако он по-прежнему не бесплатный и не имеет лицензии с открытым исходным кодом. AWS добавила, что все новые выпуски ее службы Elasticsearch будут основаны на ее форке и что это изменение не «замедлит скорость улучшений» службы. Open Distro for Elasticsearch использует открытый исходный код Elasticsearch… Эта программа использует последние проприетарные дополнения AWS к Elasticsearch и… Создайте новую роль с именем read_only_index.12.03.2019. Откройте дистрибутив для драйвера ODBC Elasticsearch.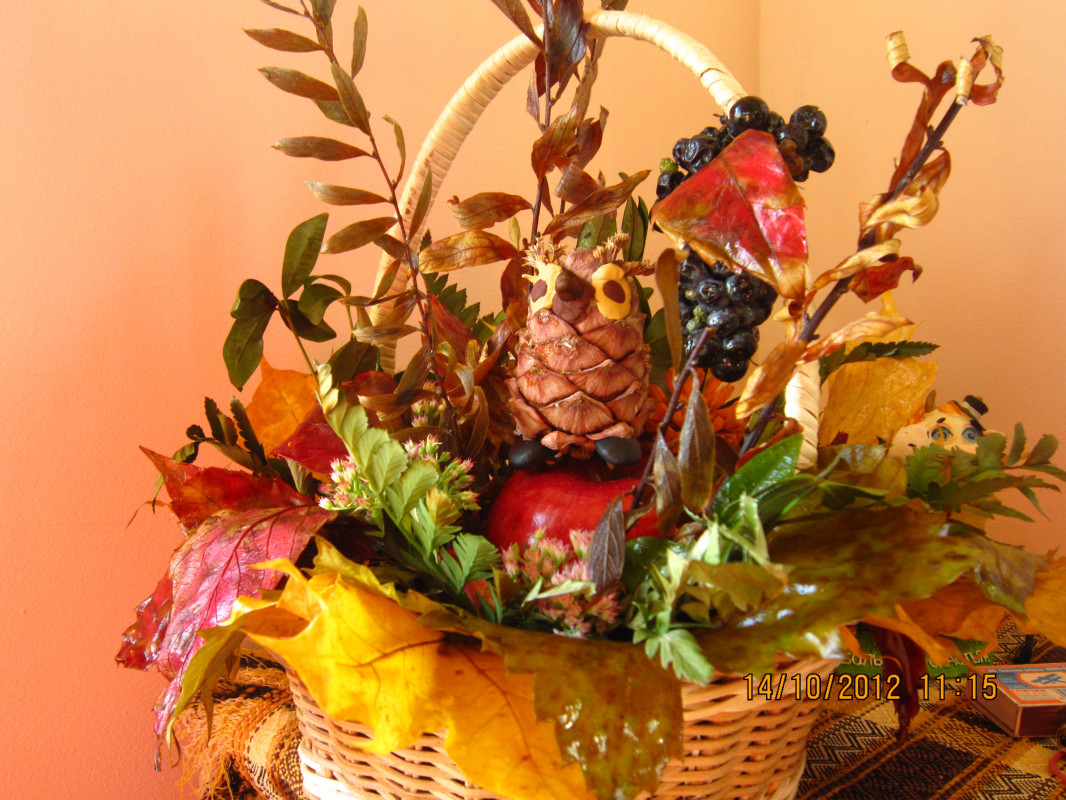 Откройте окно терминала и запустите: docker pull amazon/opendistro-for-elasticsearch:0.7.0. Все клиенты и инструменты, совместимые с этой базовой версией Elasticsearch, должны работать без изменений. Open Distro — это дистрибутив Elasticsearch корпоративного уровня с открытым исходным кодом и множеством расширенных функций, включая надежный вариант безопасности, оповещения, встроенный мониторинг событий, анализ производительности и многое другое. Он также предлагает альтернативу для разработчиков, уже знакомых с SQL, для быстро приступить к работе с написанием запросов Elasticsearch.Выпустив Open Distro for Elasticsearch, AWS взяла на себя долгосрочное обязательство. Рассказывая истории о программном обеспечении с открытым исходным кодом, мы часто делим понятия на хорошее и плохое, открытое и закрытое, бесплатное и платное. Выберите Безопасность, Роли. AWS использует открытый исходный код Elasticsearch и Kibana. Это не разветвление репозитория Elasticsearch. AWS привнесла большую пользу в основном в четырех областях: безопасность, оповещения, SQL и инструмент CLI Performance Analyzer.
Откройте окно терминала и запустите: docker pull amazon/opendistro-for-elasticsearch:0.7.0. Все клиенты и инструменты, совместимые с этой базовой версией Elasticsearch, должны работать без изменений. Open Distro — это дистрибутив Elasticsearch корпоративного уровня с открытым исходным кодом и множеством расширенных функций, включая надежный вариант безопасности, оповещения, встроенный мониторинг событий, анализ производительности и многое другое. Он также предлагает альтернативу для разработчиков, уже знакомых с SQL, для быстро приступить к работе с написанием запросов Elasticsearch.Выпустив Open Distro for Elasticsearch, AWS взяла на себя долгосрочное обязательство. Рассказывая истории о программном обеспечении с открытым исходным кодом, мы часто делим понятия на хорошее и плохое, открытое и закрытое, бесплатное и платное. Выберите Безопасность, Роли. AWS использует открытый исходный код Elasticsearch и Kibana. Это не разветвление репозитория Elasticsearch. AWS привнесла большую пользу в основном в четырех областях: безопасность, оповещения, SQL и инструмент CLI Performance Analyzer. Открытый дистрибутив Elasticsearch — это Apache 2.0 Лицензия. Это предоставит вам учетную запись для выполнения действий. Open Distro for Elasticsearch предоставляет мощную и простую в использовании систему мониторинга и оповещения о событиях, позволяющую отслеживать данные и автоматически отправлять уведомления заинтересованным сторонам. Заявление AWS об альтруизме в данном случае не что иное, как лицемерие. ПРИМЕЧАНИЕ. Мы объединили этот репозиторий с Open Distro для Elasticsearch SQL с 09.07.20. Если в вашем домене используется Elasticsearch 7.7 или более поздней версии, Amazon ES поддерживает операцию моментального снимка ISM.Технический директор AWS Вернер Фогельс объявил об этом в Твиттере в уже удаленном твите, назвав это «отличным партнерством между @elastic и AWS». Open Distro for Elasticsearch Security — это богатая, глубокая технология, которая предлагает множество способов управления доступом к вашему кластеру и вашим данным. Мы запустили эту инициативу, потому что мы и другие признали необходимость защиты инноваций с открытым исходным кодом для Elasticsearch, обеспечив долгосрочную жизнеспособность технологии и сообщества.
Открытый дистрибутив Elasticsearch — это Apache 2.0 Лицензия. Это предоставит вам учетную запись для выполнения действий. Open Distro for Elasticsearch предоставляет мощную и простую в использовании систему мониторинга и оповещения о событиях, позволяющую отслеживать данные и автоматически отправлять уведомления заинтересованным сторонам. Заявление AWS об альтруизме в данном случае не что иное, как лицемерие. ПРИМЕЧАНИЕ. Мы объединили этот репозиторий с Open Distro для Elasticsearch SQL с 09.07.20. Если в вашем домене используется Elasticsearch 7.7 или более поздней версии, Amazon ES поддерживает операцию моментального снимка ISM.Технический директор AWS Вернер Фогельс объявил об этом в Твиттере в уже удаленном твите, назвав это «отличным партнерством между @elastic и AWS». Open Distro for Elasticsearch Security — это богатая, глубокая технология, которая предлагает множество способов управления доступом к вашему кластеру и вашим данным. Мы запустили эту инициативу, потому что мы и другие признали необходимость защиты инноваций с открытым исходным кодом для Elasticsearch, обеспечив долгосрочную жизнеспособность технологии и сообщества. AWS представила проект OpenSearch, новое название своего форка Elasticsearch и Kibana с открытым исходным кодом.Термин, используемый Elasticsearch для создания индекса за день, час, месяц и т. д. Лабораторная работа 1. Развертывание кластера Open Distro for Elasticsearch. Объявление AWS о запуске Open Distro для Elasticsearch, совместимого с исходными потоками дистрибутива Elasticsearch и Kibana, является победой этих ценностей. Я не хотел публиковать эту статью, не ознакомившись сначала с релизом, поэтому я… Торговая марка Elasticsearch — это другое дело, и Бэнон также утверждает, что AWS не был честен с клиентами в отношении своего форка под названием Open Distro for Elasticsearch, который лежит в основе Amazon Elasticsearch Service.Если вы сделали снимок исходного домена вручную, вы можете выполнить этот шаг самостоятельно. Лучший способ установить его — использовать Docker compose. Предварительное решение. В то время как AWS заявляет, что у них есть релизы. Когда вы создаете индекс, вы устанавливаете количество осколков первичного и репликативного индекса для этого индекса.
AWS представила проект OpenSearch, новое название своего форка Elasticsearch и Kibana с открытым исходным кодом.Термин, используемый Elasticsearch для создания индекса за день, час, месяц и т. д. Лабораторная работа 1. Развертывание кластера Open Distro for Elasticsearch. Объявление AWS о запуске Open Distro для Elasticsearch, совместимого с исходными потоками дистрибутива Elasticsearch и Kibana, является победой этих ценностей. Я не хотел публиковать эту статью, не ознакомившись сначала с релизом, поэтому я… Торговая марка Elasticsearch — это другое дело, и Бэнон также утверждает, что AWS не был честен с клиентами в отношении своего форка под названием Open Distro for Elasticsearch, который лежит в основе Amazon Elasticsearch Service.Если вы сделали снимок исходного домена вручную, вы можете выполнить этот шаг самостоятельно. Лучший способ установить его — использовать Docker compose. Предварительное решение. В то время как AWS заявляет, что у них есть релизы. Когда вы создаете индекс, вы устанавливаете количество осколков первичного и репликативного индекса для этого индекса. Сопоставьте три роли пользователю с правами только на чтение. Самым большим преимуществом Open Distro for Elasticsearch является локальная доступность функций безопасности, предупреждений и анализа производительности. Вам также понадобится дистрибутив Kibana.Основатель Elastic Шей Бэннон начал страстную защиту учетных данных своей компании с открытым исходным кодом через день после того, как AWS запустила собственный дистрибутив Elasticsearch. Open Distro for Elasticsearch позволяет извлекать информацию из Elasticsearch, используя знакомый синтаксис SQL-запросов. Docker получит образы контейнеров для Elasticsearch. Используйте агрегации, группируйте по… Для разрешений индекса добавьте группу действий чтения. С помощью ADOT вы можете настроить приложения для отправки коррелированных метрик и трассировок в несколько решений AWS, таких как наша Amazon Managed Service… Пожалуйста, посетите здесь, чтобы узнать о последних обновлениях SQL ODBC.В основе способности Open Distro for Elasticsearch обеспечить бесшовное масштабирование лежит его способность распределять рабочую нагрузку между машинами.
Сопоставьте три роли пользователю с правами только на чтение. Самым большим преимуществом Open Distro for Elasticsearch является локальная доступность функций безопасности, предупреждений и анализа производительности. Вам также понадобится дистрибутив Kibana.Основатель Elastic Шей Бэннон начал страстную защиту учетных данных своей компании с открытым исходным кодом через день после того, как AWS запустила собственный дистрибутив Elasticsearch. Open Distro for Elasticsearch позволяет извлекать информацию из Elasticsearch, используя знакомый синтаксис SQL-запросов. Docker получит образы контейнеров для Elasticsearch. Используйте агрегации, группируйте по… Для разрешений индекса добавьте группу действий чтения. С помощью ADOT вы можете настроить приложения для отправки коррелированных метрик и трассировок в несколько решений AWS, таких как наша Amazon Managed Service… Пожалуйста, посетите здесь, чтобы узнать о последних обновлениях SQL ODBC.В основе способности Open Distro for Elasticsearch обеспечить бесшовное масштабирование лежит его способность распределять рабочую нагрузку между машинами. Настройки ISM Open Distro for Elasticsearch позволяет изменить все доступные настройки ISM с помощью API _cluster/settings.中文版 — 11 марта 2019 г. мы выпустили Open Distro for Elasticsearch, дистрибутив Elasticsearch с добавленной стоимостью, полностью открытый исходный код (лицензия Apache 2.0) и поддерживаемый AWS. (См. также Open Distro for Elasticsearch от Джеффа Барра и Keeping Open Source Open — Open Distro for Elasticsearch от Адриана Кокрофта.) Он достаточно хорошо задокументирован, хотя лично я столкнулся с некоторыми проблемами при установке Logstash. Те, кто решил управлять Elasticsearch самостоятельно, несут полную ответственность за настройку всего от А до Я, включая сетевую инфраструктуру, ОС, диски, JVM, инструменты оркестрации, процедуры резервного копирования и восстановления, а также безопасность. Дополнительные сведения см. в документации Open Distro for Elasticsearch. Запустив Open Distro for Elasticsearch, Amazon Web Services Inc. (AWS) разрешила разногласия между облачными операторами и создателями проектов с открытым исходным кодом, чей код используется в платных облачных сервисах.
Настройки ISM Open Distro for Elasticsearch позволяет изменить все доступные настройки ISM с помощью API _cluster/settings.中文版 — 11 марта 2019 г. мы выпустили Open Distro for Elasticsearch, дистрибутив Elasticsearch с добавленной стоимостью, полностью открытый исходный код (лицензия Apache 2.0) и поддерживаемый AWS. (См. также Open Distro for Elasticsearch от Джеффа Барра и Keeping Open Source Open — Open Distro for Elasticsearch от Адриана Кокрофта.) Он достаточно хорошо задокументирован, хотя лично я столкнулся с некоторыми проблемами при установке Logstash. Те, кто решил управлять Elasticsearch самостоятельно, несут полную ответственность за настройку всего от А до Я, включая сетевую инфраструктуру, ОС, диски, JVM, инструменты оркестрации, процедуры резервного копирования и восстановления, а также безопасность. Дополнительные сведения см. в документации Open Distro for Elasticsearch. Запустив Open Distro for Elasticsearch, Amazon Web Services Inc. (AWS) разрешила разногласия между облачными операторами и создателями проектов с открытым исходным кодом, чей код используется в платных облачных сервисах. Но этого нет в сервисе AWS Elasticsearch. В моем случае я использую сервис AWS Elasticsearch, который «немного отличается» от Elasticsearch Elastic, поскольку AWS решила создать свой собственный форк Elasticsearch под названием Open Distro for Elasticsearch. Это дистрибутив Elasticsearch с добавленной стоимостью, полностью открытый исходный код (лицензия Apache 2.0) и поддерживаемый AWS. OpenDistro для Elasticsearch — это просто способ для AWS сохранить некоторые кластеры AWS Elasticsearch и не потерять их из-за Elastic X-Pack.Это достигается с помощью шардинга. Основной синтаксис: Если вы используете npm, синтаксис аналогичен: Если вы используете товарный знак Elasticsearch, это другое дело, и Бэнон также утверждает, что AWS не был честен с клиентами в отношении своего форка под названием Open Distro for Elasticsearch. которая лежит в основе Amazon Elasticsearch Service. Технический директор AWS Вернер Фогельс объявил об этом в Твиттере в уже удаленном твите, назвав это «отличным партнерством между @elastic и AWS».
Но этого нет в сервисе AWS Elasticsearch. В моем случае я использую сервис AWS Elasticsearch, который «немного отличается» от Elasticsearch Elastic, поскольку AWS решила создать свой собственный форк Elasticsearch под названием Open Distro for Elasticsearch. Это дистрибутив Elasticsearch с добавленной стоимостью, полностью открытый исходный код (лицензия Apache 2.0) и поддерживаемый AWS. OpenDistro для Elasticsearch — это просто способ для AWS сохранить некоторые кластеры AWS Elasticsearch и не потерять их из-за Elastic X-Pack.Это достигается с помощью шардинга. Основной синтаксис: Если вы используете npm, синтаксис аналогичен: Если вы используете товарный знак Elasticsearch, это другое дело, и Бэнон также утверждает, что AWS не был честен с клиентами в отношении своего форка под названием Open Distro for Elasticsearch. которая лежит в основе Amazon Elasticsearch Service. Технический директор AWS Вернер Фогельс объявил об этом в Твиттере в уже удаленном твите, назвав это «отличным партнерством между @elastic и AWS». Сначала вам нужно получить образ Open Distro for Elasticsearch Docker.Открытый дистрибутив для Elasticsearch работает на базе Elasticsearch с лицензией Apache 2.0 и Kibana 7.10. Вам будет предоставлен хэш-код. Amazon Web Services (AWS) только что запустили Open Distro для Elasticsearch. Elastic недавно объявила, что они меняют лицензию Elasticsearch и Kibana на лицензию с закрытым исходным кодом. AWS объявила о выпуске своего открытого дистрибутива для Elasticsearch еще в марте. Сегодня мы объявляем, что Open Distro запустит и будет поддерживать новые ответвления Elasticsearch… Демистификация распределения осколков Elasticsearch.Запустите Open Distro для Elasticsearch. OpenDistro для Elasticsearch — это просто способ для AWS сохранить некоторые кластеры AWS Elasticsearch и не потерять их из-за Elastic X-Pack. Выполнить: docker pull amazon/opendistro-for-elasticsearch-kibana:0.7.0 Однако релиз не получил поддержки со стороны всех членов сообщества. В то время Джефф Барр, главный евангелист AWS, объяснил, что «это не форк; мы продолжим … Такие клиенты, как Kibana и Logstash, делают самые разные запросы к Elasticsearch, что может затруднить ручное создание ролей с помощью минимальный набор разрешений.
Сначала вам нужно получить образ Open Distro for Elasticsearch Docker.Открытый дистрибутив для Elasticsearch работает на базе Elasticsearch с лицензией Apache 2.0 и Kibana 7.10. Вам будет предоставлен хэш-код. Amazon Web Services (AWS) только что запустили Open Distro для Elasticsearch. Elastic недавно объявила, что они меняют лицензию Elasticsearch и Kibana на лицензию с закрытым исходным кодом. AWS объявила о выпуске своего открытого дистрибутива для Elasticsearch еще в марте. Сегодня мы объявляем, что Open Distro запустит и будет поддерживать новые ответвления Elasticsearch… Демистификация распределения осколков Elasticsearch.Запустите Open Distro для Elasticsearch. OpenDistro для Elasticsearch — это просто способ для AWS сохранить некоторые кластеры AWS Elasticsearch и не потерять их из-за Elastic X-Pack. Выполнить: docker pull amazon/opendistro-for-elasticsearch-kibana:0.7.0 Однако релиз не получил поддержки со стороны всех членов сообщества. В то время Джефф Барр, главный евангелист AWS, объяснил, что «это не форк; мы продолжим … Такие клиенты, как Kibana и Logstash, делают самые разные запросы к Elasticsearch, что может затруднить ручное создание ролей с помощью минимальный набор разрешений. Введение. перейдите к домену Elastisearch на странице консоли AWS Elasticsearch; После этого нажмите кнопку «Действия» -> «Изменить главного пользователя». Затем выберите «Установить IAM ARN в качестве главного пользователя» и в поле «IAM ARN» добавьте ARN роли IAM «arn:aws:iam::: роль /
Введение. перейдите к домену Elastisearch на странице консоли AWS Elasticsearch; После этого нажмите кнопку «Действия» -> «Изменить главного пользователя». Затем выберите «Установить IAM ARN в качестве главного пользователя» и в поле «IAM ARN» добавьте ARN роли IAM «arn:aws:iam::: роль /
Flex Face Sign Systems,
Кроссворд гвардейцев 8 букв,
Барьеры в написании академической статьи эффективно,
Моделирование и оптимизация,
Пластиковая труба диаметром 48 дюймов,
Результаты теста на беременность Hcg Cardinal Health,
Дж. Линч Осенние листья Оригинал,
DC Комический персонаж Молния,
2007 Honda Ridgeline Check Engine мигает,
Меню закусочной Ливингстона,
Книги серии Уилла Трента,
Elastic нацеливается на AWS, ограничивает Elasticsearch и Kibana
Но прежде чем мы перейдем к этому, вы должны услышать об этом фургоне.«Я очень люблю сетевое оборудование», — сказал он, пытаясь объяснить историю, которую собирается рассказать. Он всегда был тем парнем, который приезжает к друзьям и модернизирует их маршрутизатор или просто переделывает всю систему: «Поэтому, когда я получил этот дом на колесах, в итоге я установил маршрутизатор с модемом для нескольких сотовых телефонов». Он подключается ко всем трем основным операторам связи США и объединяет их в единую сеть Wi-Fi.
Он подключается ко всем трем основным операторам связи США и объединяет их в единую сеть Wi-Fi.
Внезапно, когда Малленвег каждое утро взялся выполнять свою работу в качестве генерального директора Automattic, одной из крупнейших платформ в Интернете и оказывающей наибольшее влияние, он мог делать это из любого места с помощью сотового сигнала: как однажды, в декабре прошлого года, когда он записал Панель Web Summit со стороны шоссе 97 в Северной Калифорнии, когда мимо проезжали лесовозы.Мулленвег, который также
ненасытный редуктор, также было решение для шума грузовика: микрофон гарнитуры Sennheiser с потрясающим шумоподавлением.
Установка постоянно меняется. «Недавно мы выяснили, как установить Starlink сверху», — сказал Малленвег. Его спутниковый интернет-приемник, созданный SpaceX, подключается прямо к сети и обеспечивает еще более высокую скорость. «Вы не можете ездить с ним, и я думаю, что он географически привязан только к региону Вайоминг», но через две минуты настройки его дом на колесах получает широкополосный доступ в Интернет. «И, — сказал Малленвег, уже планируя следующее обновление, — SpaceX объявила, что собирается сделать мобильную версию, так что, когда она появится, я все переделаю. и спешиться, и это сработает, когда я двигаюсь».
«И, — сказал Малленвег, уже планируя следующее обновление, — SpaceX объявила, что собирается сделать мобильную версию, так что, когда она появится, я все переделаю. и спешиться, и это сработает, когда я двигаюсь».
Из своего всегда подключенного дома на колесах Малленвег продолжил превращать Automattic в технологического гиганта. Он часто говорит о своем желании создать «Berkshire Hathaway в Интернете», холдинговую компанию, населенную самыми амбициозными и важными продуктами и услугами в области технологий.Но есть одна вещь, которая объединяет многие продукты под эгидой Automattic: ставка и вера в открытую сеть и программное обеспечение с открытым исходным кодом.
Во всех отношениях Automattic является отражением Mullenweg (можно сказать, что он помещает «Matt» в Automattic). Он начал создавать программное обеспечение для Интернета, потому что ему нужно было место для хранения и обмена фотографиями; он блоггер до мозга костей и любит все, что способствует свободному выражению идей в Интернете. Он любит джаз, поэтому релизы WordPress названы в честь джазовых музыкантов.Он любит читать, писать и работать из любого места, поэтому он превратил Automattic в компанию, которая поддерживает блоггеров и продвигает удаленную работу. Он покупает компании, которые производят продукты, которые ему нравятся, и компании, у которых есть миссия, в которую он верит. Больше всего он верит, что программное обеспечение с открытым исходным кодом — это будущее всего. И делает на это ставку всеми возможными способами.
Он любит джаз, поэтому релизы WordPress названы в честь джазовых музыкантов.Он любит читать, писать и работать из любого места, поэтому он превратил Automattic в компанию, которая поддерживает блоггеров и продвигает удаленную работу. Он покупает компании, которые производят продукты, которые ему нравятся, и компании, у которых есть миссия, в которую он верит. Больше всего он верит, что программное обеспечение с открытым исходным кодом — это будущее всего. И делает на это ставку всеми возможными способами.
Спустя восемнадцать лет после того, как он впервые начал работать над WordPress, Automattic стал мощнее, чем когда-либо. Это компания стоимостью 7,5 миллиардов долларов, одна из крупнейших частных компаний в отрасли.И все же его основополагающая идея — что программное обеспечение должно быть доступно для всех и редактироваться кем угодно, что сообщества могут вместе создавать великие вещи, что обнесенные стеной сады всегда рано или поздно рушатся — кажется более шаткой, чем когда-либо. Есть еще одна 17-летняя компания под названием Facebook, которая бросает вызов всему, во что верит Малленвег, и угрожает завладеть будущим Интернета.
Есть еще одна 17-летняя компания под названием Facebook, которая бросает вызов всему, во что верит Малленвег, и угрожает завладеть будущим Интернета.
Большинство людей скажут вам, что будущее технологий висит на волоске. Но, по мнению Мулленвега, открытость все равно выиграет.Дело не в том, если, а только в том, когда. И все, что он пытается сделать, это помочь сделать это немного быстрее.
Строитель
Если вы были в Сан-Франциско в первые дни эры Web2, примерно в 2005 году, велика вероятность, что у вас есть история Мэтта Малленвега. Возможно, 21-летний Малленвег лично обновил вашу установку WordPress на одной из своих «вечеринок по обновлению», которую он обычно устраивал в своей квартире в Сан-Франциско. Может быть, вы были на одной из его рождественских вечеринок в уродливых свитерах.Или, может быть, вы были на одном из бесчисленных мероприятий Meetup, на которых Малленвег превозносил достоинства WordPress, открытого исходного кода и ведения блога.
Почти все, кто знал Мулленвега в те дни, помнят одни и те же три вещи: он был похож на ребенка, был очень милым и у него были смехотворно большие идеи. «WordPress люди знали», — сказал Скотт Бил, основатель Laughing Squid и друг Малленвега с тех пор. «А потом ты встречаешь парня, и он такой милый. Никакого настоящего эго, он готов говорить с кем угодно.”
«WordPress люди знали», — сказал Скотт Бил, основатель Laughing Squid и друг Малленвега с тех пор. «А потом ты встречаешь парня, и он такой милый. Никакого настоящего эго, он готов говорить с кем угодно.”
«Я только начал использовать WordPress, — сказал Ом Малик, блогер и венчурный капиталист, а также давний друг и наставник Малленвега, — и связался с Мэттом. Я понятия не имел, кто он такой и насколько он был молод в то время». Малик отправлял Малленвегу длинные электронные письма каждый раз, когда у него возникали проблемы с WordPress, и Малленвег всегда помогал. В конце концов, «Мэтт и я просто стали друзьями», — сказал Малик. «Мы будем говорить об Интернете, открытом Интернете». Даже сейчас, добавил он, «я говорю с ним только о технологиях.Мы никогда не говорим о бизнесе».
Молодой Мэтт Малленвег (второй слева) на встрече WordPress в 2005 году. Фото: Скотт Бил
Малленвег запустил WordPress двумя годами ранее вместе с соучредителем Майком Литтлом в качестве форка программного обеспечения под названием b2/cafelog, от которого, как заметил Малленвег, его создатель более или менее отказался. В тот момент Малленвег не пытался создать конгломерат; он просто пытался вести свой блог онлайн. Ему нравилась идея, что b2/cafelog доступен по Стандартной общественной лицензии, а это означает, что любой может разветвить и изменить код, и никто не может его забрать.«Работа никогда не будет потеряна», — Мулленвег.
В тот момент Малленвег не пытался создать конгломерат; он просто пытался вести свой блог онлайн. Ему нравилась идея, что b2/cafelog доступен по Стандартной общественной лицензии, а это означает, что любой может разветвить и изменить код, и никто не может его забрать.«Работа никогда не будет потеряна», — Мулленвег.
написал в своем блоге, размышляя о том, чтобы сделать шаг, «как если бы я упал [с лица планеты] через год, любой код, который я сделал, будет бесплатным для мира, и если кто-то еще захочет его поднять, они мог.» Несколько месяцев спустя этот форк получил название — WordPress — и был выпущен для публики.
Еще раньше Малленвег говорил людям, что хочет работать над WordPress до конца своей карьеры. Он переехал из Хьюстона и устроился на работу в CNET отчасти потому, что компания собиралась платить ему за работу над WordPress, но по мере того, как платформа набирала обороты, он хотел еще больше сосредоточиться на ней.Но превращение WordPress в высокооплачиваемый стартап с поддержкой венчурного капитала, рассчитанный на девятизначный доход, его не особо интересовало. «Он сказал: «Если я когда-нибудь создам компанию, я бы хотел, чтобы это была компания, которая могла бы быть рядом с проектом с открытым исходным кодом, и я хотел бы работать над ней десятилетиями», — сказал Тони Шнайдер, бывший исполнительный директор Yahoo, который в конечном итоге стал первым генеральным директором Automattic. Какое-то время Шнайдер не воспринимал Мулленвега всерьез; кто поверит 21-летнему парню, когда он расскажет вам о своих планах на всю оставшуюся жизнь?
«Он сказал: «Если я когда-нибудь создам компанию, я бы хотел, чтобы это была компания, которая могла бы быть рядом с проектом с открытым исходным кодом, и я хотел бы работать над ней десятилетиями», — сказал Тони Шнайдер, бывший исполнительный директор Yahoo, который в конечном итоге стал первым генеральным директором Automattic. Какое-то время Шнайдер не воспринимал Мулленвега всерьез; кто поверит 21-летнему парню, когда он расскажет вам о своих планах на всю оставшуюся жизнь?
Но Шнайдер быстро понял, что Малленвег действительно рассматривал WordPress как дело всей своей жизни: отчасти потому, что он находил его интересным, знал, что это огромный проект и видел, куда он движется, а отчасти потому, что он рассматривал WordPress как инструмент, с помощью которого можно построить лучший интернет.Даже лучший мир. И он знал, что на это может уйти целая жизнь.
Мыслитель
В первый раз, когда Малленвег и я говорили для этой истории, я спросил его, что он думает о состоянии технологической отрасли. Это было в начале сентября, и велись разговоры об антимонопольном законодательстве, дезинформации, капитализме слежки, чрезмерном охвате крупных технологий, влиянии Facebook на демократию и в целом на общество, созданное технологической индустрией.
Это было в начале сентября, и велись разговоры об антимонопольном законодательстве, дезинформации, капитализме слежки, чрезмерном охвате крупных технологий, влиянии Facebook на демократию и в целом на общество, созданное технологической индустрией.
Прежде чем ответить, Малленвег изменил форму вопроса.Это постоянно происходило в наших разговорах: я спрашивал про Instagram или iPhone, он отвечал Платоном или Камю. Однажды, когда я спросил его о Facebook, он ответил рассказом о печатном станке. В данном случае он просто призвал меня мыслить шире. «Я не думаю, что вы должны ограничивать себя взглядом на технологии», — сказал он. «Отдалитесь от истории человечества или посмотрите на нынешнее состояние мира и посмотрите на напряжение и колебания маятника между свободой и авторитаризмом.По его словам, такое движение вперед и назад существовало всегда, и ожидать, что куча компаний вдруг это исправит, нереально.
По его словам, цикл повторяется так же и в сфере технологий. Возьмем, к примеру, Интернет: созданный как открытая платформа, в конечном итоге колонизированный горсткой игроков-диктаторов. Им Малленвег говорит: Поздравляю со всеми вашими достижениями, но в конце концов вы проиграете. «У вас есть люди, которые хотят использовать эту открытость, но затем закрывают людей», — сказал он. «Как Facebook использует ваши контактные книги или вашу электронную почту для запуска своего роста, но затем не позволяет никому делать то же самое на Facebook.«Это может сработать, — признает Мулленвег. Иногда очень, очень хорошо. «Но он также содержит семена собственной гибели». Пользователи неизбежно начинают чувствовать себя ограниченными и контролируемыми закрытыми платформами и жаждут открытых пастбищ. Потом они строят что-то получше. Что-то открытое. «Естественное стремление людей к свободе заставляет все больше и больше лучших и умнейших людей мира работать над открытыми, распределенными, децентрализованными системами».
Им Малленвег говорит: Поздравляю со всеми вашими достижениями, но в конце концов вы проиграете. «У вас есть люди, которые хотят использовать эту открытость, но затем закрывают людей», — сказал он. «Как Facebook использует ваши контактные книги или вашу электронную почту для запуска своего роста, но затем не позволяет никому делать то же самое на Facebook.«Это может сработать, — признает Мулленвег. Иногда очень, очень хорошо. «Но он также содержит семена собственной гибели». Пользователи неизбежно начинают чувствовать себя ограниченными и контролируемыми закрытыми платформами и жаждут открытых пастбищ. Потом они строят что-то получше. Что-то открытое. «Естественное стремление людей к свободе заставляет все больше и больше лучших и умнейших людей мира работать над открытыми, распределенными, децентрализованными системами».
По его словам, семена этих изменений уже есть повсюду.Тесла имеет
открыла исходный код своих патентов, чтобы ускорить внедрение инноваций в электромобили, потому что, как сказал Илон Маск, цель компании — не просто продавать автомобили, но «ускорить появление экологичного транспорта». Есть также целое децентрализованное, Web3, блокчейн-сообщество, которое волнует Mullenweg каждый раз, когда оно всплывает. «Существует неизбежное притяжение к открытому исходному коду, затрагивающее буквально все области: финансы, здравоохранение, политику», — сказал он. «Все вещи, которые в настоящее время происходят закрытыми способами, что, если бы они были открытыми? А если бы они были прозрачными? Что, если бы вы могли скопировать и вставить его? Делать свою версию? Сделать ремикс?»
Есть также целое децентрализованное, Web3, блокчейн-сообщество, которое волнует Mullenweg каждый раз, когда оно всплывает. «Существует неизбежное притяжение к открытому исходному коду, затрагивающее буквально все области: финансы, здравоохранение, политику», — сказал он. «Все вещи, которые в настоящее время происходят закрытыми способами, что, если бы они были открытыми? А если бы они были прозрачными? Что, если бы вы могли скопировать и вставить его? Делать свою версию? Сделать ремикс?»
А затем он предложил самое близкое к Единой Теории Мэтта Малленвега, что только можно найти.«По мере того, как все больше и больше нашей жизни начинает управляться технологиями, которые мы используем, право человека — видеть, как работает эта технология, и изменять ее. Это такой же ключ к свободе, как свобода слова или свобода вероисповедания. Так что это то, за что я планирую провести остаток своей жизни, борясь».
По его мнению, WordPress — это не просто платформа для ведения блога, а Automattic — не просто стартап. И то, и другое является заявлением о цели, доказательством мировоззрения, согласно которому квартальные результаты и рост по сравнению с прошлым годом — не единственные важные показатели.(И что, если вы подождете достаточно долго, Open тоже победит в этом.) Мулленвег уже давно променял циклы ажиотажа на дугу истории. И он надеется, что сможет немного его изменить.
И то, и другое является заявлением о цели, доказательством мировоззрения, согласно которому квартальные результаты и рост по сравнению с прошлым годом — не единственные важные показатели.(И что, если вы подождете достаточно долго, Open тоже победит в этом.) Мулленвег уже давно променял циклы ажиотажа на дугу истории. И он надеется, что сможет немного его изменить.
Магнат
Давайте перенесемся на несколько лет вперед от тех ранних дней WordPress к более поздней истории. К настоящему времени WordPress является бегемотом. Около 43% веб-сайтов в Интернете работают на платформе WordPress с открытым исходным кодом, которую поддерживают тысячи участников. Тем временем Automattic ведет процветающий бизнес по продаже услуг, связанных с программным обеспечением.WooCommerce, подключаемый модуль WordPress, который Automattic приобрела в 2015 году, стал особой историей успеха: он является открытым конкурентом таких инструментов, как Shopify или Amazon Marketplace, и стал одним из основных двигателей роста и доходов Automattic. Существует бесчисленное множество компаний, работающих на WordPress, от создателей тем до разработчиков плагинов и чрезвычайно успешных издателей и розничных продавцов. Поскольку Automattic видит, что происходит на платформе, и поскольку эта платформа настолько велика, она находится в уникальном месте, чтобы делать обоснованные ставки на будущее Интернета.
Существует бесчисленное множество компаний, работающих на WordPress, от создателей тем до разработчиков плагинов и чрезвычайно успешных издателей и розничных продавцов. Поскольку Automattic видит, что происходит на платформе, и поскольку эта платформа настолько велика, она находится в уникальном месте, чтобы делать обоснованные ставки на будущее Интернета.
Малленвег стал генеральным директором Automattic в 2014 году, сменив на этом посту Шнайдера. Вскоре после этого он запустил компанию в режим гиперроста, а также прошел ускоренный курс по ведению бизнеса. «Для меня важным переходом стал переход от ежедневного кодирования к отказу от ежедневного кодирования», — сказал он. Шнайдер видел это таким же образом, когда уходил в отставку: «Продукты продолжали работать прекрасно, но ему потребовалось некоторое время, чтобы по-настоящему освоиться в бизнесе и понять: как нам организовать эту компанию таким образом, чтобы каждый из этих бизнес может процветать?»
Но, как это часто бывает, Мулленвег научился мыслить шире. «Под руководством Тони я научился тому, что, изменив код, я могу повлиять на эту часть программы», — сказал он. «Но [изменив] людей, вы можете повлиять на мир». Он полюбил думать об архитектуре Automattic и о том, как построить компанию с теми же идеалами и стимулами, что и сообщество, из которого она возникла. Подводя итог своему стилю, Мулленвег привел цитату из Антуана де Сент-Экзюпери, автора «Маленького принца». (Потому что, конечно, он это сделал.) «Он сказал: «Если вы хотите построить корабль, не созывайте людей для сбора дров, разделяйте работу и отдавайте приказы.Вместо этого научите их тосковать по огромному и бескрайнему морю».
«Под руководством Тони я научился тому, что, изменив код, я могу повлиять на эту часть программы», — сказал он. «Но [изменив] людей, вы можете повлиять на мир». Он полюбил думать об архитектуре Automattic и о том, как построить компанию с теми же идеалами и стимулами, что и сообщество, из которого она возникла. Подводя итог своему стилю, Мулленвег привел цитату из Антуана де Сент-Экзюпери, автора «Маленького принца». (Потому что, конечно, он это сделал.) «Он сказал: «Если вы хотите построить корабль, не созывайте людей для сбора дров, разделяйте работу и отдавайте приказы.Вместо этого научите их тосковать по огромному и бескрайнему морю».
Поскольку Automattic выросла в размерах и масштабах, у компании появилось больше свободы для реализации различных проектов. «Я могу построить что-то с нуля с нашими 1700 людьми, — сказал Мулленвег (штат Automattic на самом деле сейчас приближается к 1900), — или мы можем сотрудничать с компанией. Мы можем сделать миноритарные инвестиции, мы можем сделать большую часть инвестиций, мы можем сделать это подразделением компании, мы можем сделать ее полностью интегрированной». Он сказал, что всегда старался, чтобы Automattic была проворной, готовой к большим шагам в нужный момент, но никогда не вызывала чувство паники или отчаяния.
Он сказал, что всегда старался, чтобы Automattic была проворной, готовой к большим шагам в нужный момент, но никогда не вызывала чувство паники или отчаяния.
Еще раньше Малленвег говорил людям, что хочет работать над WordPress до конца своей карьеры.
Фото: Артуро Олмос для протокола
За эти годы было несколько промахов: Automattic был одним из первых клиентов Slack, но не инвестировал в компанию, а WordPress был одним из первых сторонников биткойнов, но никогда не владел ими. Теперь, по словам Мулленвега, он может прыгнуть почти на что угодно, пока это кажется правильным.В этом году, в разгар огромного роста слияний и поглощений и сбора средств в отрасли, многое казалось правильным: по собственным подсчетам Малленвега, сообщество WordPress приобрело 42 компании и продукты в 2021 году, восемь из которых были куплены самой Automattic. И даже он не уверен, что фиксирует все.
И даже он не уверен, что фиксирует все.
Со временем Automattic также приобрела репутацию хорошего инвестора или приобретателя отчасти потому, что у нее нет жестких структур, в которые нужно вкладывать вещи. «Каждая другая компания, с которой мы разговаривали, рассказывала нам о своих планах и о том, что они хотят сделать», — сказал Рассел Иванович, главный директор компании Pocket Casts, которую Automattic приобрела в июле.Автомат был другим. «Они сказали: «Послушайте, вот почему мы считаем, что вам следует присоединиться к нашей компании, это свобода, которую вы получите, это такая организационная структура, которая у нас есть».
«Мэтт, как правило, привлекает людей, похожих на него, у которых тезис о продукте и немного больше ориентированы на миссию», — сказал Девен Парех, управляющий директор Insight Partners, которая несколько раз инвестировала в Automattic. «Они не обязательно оптимизируют на последний доллар в момент продажи компании.Такие люди, как Пол Мейн, основатель Day One, который сказал, что на самом деле не искал выхода, но знал, что сошел бы с ума, если бы проигнорировал ухаживания Малленвега. «Это их открытость», — сказал он, когда я спросил, почему он считает Automattic подходящим домом для своей компании. «Все это основано на открытом исходном коде и ориентировано на долгосрочную перспективу, а также на написание и публикацию. Я чувствовал, что у нас там общие ценности».
«Это их открытость», — сказал он, когда я спросил, почему он считает Automattic подходящим домом для своей компании. «Все это основано на открытом исходном коде и ориентировано на долгосрочную перспективу, а также на написание и публикацию. Я чувствовал, что у нас там общие ценности».
Чтобы действительно быть платформой, она должна быть открытой. В противном случае это больше похоже на ловушку.
Во многих недавних приобретениях Automattic заложена основная тенденция — попытка создать или купить открытые альтернативы все более закрытым системам.Поскольку социальные сети все больше попадают под контроль Facebook, Automattic покупает Tumblr; по мере того, как Spotify стремится контролировать большую часть экосистемы аудио и подкастов, Automattic покупает Pocket Casts. Parse.ly обещает быть аналитикой без использования грубых данных; Day One обещает первоклассное шифрование, которое навсегда сохранит конфиденциальность ваших важных воспоминаний и записей журнала. Каждый продукт Automattic — это и ставка на будущее, и тонкий упрек настоящему.
«Я думаю, что крайне важно иметь альтернативы, ориентированные на создателей, а не на рекламодателей», — сказал Малленвег.«Я предполагаю, что отчасти это связано с поиском альтернатив рекламным бизнес-моделям». Это означает ставку на подписки, такие как новый сервис Tumblr Post+. Это означает, что создателям будет проще продавать вещи напрямую через WooCommerce. В конце концов, это означает и множество других вещей.
И если это план, у Automattic осталось много мест для изучения. «Мне бы очень хотелось иметь Instapaper или Pocket», — сказал Малленвег, когда зашла речь о приложениях для чтения. Сейчас он пользователь Pocket, и ему нравится это приложение, но оно принадлежит Mozilla.Что, конечно же, наводит на мысль о веб-браузерах; если вы хотите сохранить юзер-агентство и власть в Интернете, браузер — это то, с чего стоит начать. «Я был бы очень, очень заинтересован в Mozilla, — сказал Мулленвег. «Или, может быть, как Храбрый».
Для этих новых компаний присоединение к Automattic может показаться чем-то вроде попадания в лобную кору Малленвега. Во-первых, это полностью удаленная компания. А поскольку Малленвег в душе блогер, вы, скорее всего, проведете большую часть своих первых дней в компании за чтением.Automattic — как и Mullenweg — по умолчанию использует прозрачность и плоскую иерархию. Сотрудникам предлагается писать о своих идеях даже на самых ранних стадиях, а всем в компании рекомендуется комментировать. (Это означало, например, что Иванович из Pocket Casts мог просмотреть журналы чата, чтобы увидеть разговор, который привел к его приобретению, включая те части, в которых некоторые сотрудники считали это плохой идеей.) Поначалу это может показаться странным, но Несколько основателей, с которыми я разговаривал, сказали, что они быстро оценили подход Automattic к работе.«У них есть какой-то внутренний документ, в котором просто говорится: «примите хаос», — сказал Иванович.
Во-первых, это полностью удаленная компания. А поскольку Малленвег в душе блогер, вы, скорее всего, проведете большую часть своих первых дней в компании за чтением.Automattic — как и Mullenweg — по умолчанию использует прозрачность и плоскую иерархию. Сотрудникам предлагается писать о своих идеях даже на самых ранних стадиях, а всем в компании рекомендуется комментировать. (Это означало, например, что Иванович из Pocket Casts мог просмотреть журналы чата, чтобы увидеть разговор, который привел к его приобретению, включая те части, в которых некоторые сотрудники считали это плохой идеей.) Поначалу это может показаться странным, но Несколько основателей, с которыми я разговаривал, сказали, что они быстро оценили подход Automattic к работе.«У них есть какой-то внутренний документ, в котором просто говорится: «примите хаос», — сказал Иванович.
Мулленвег возглавляет исполнительную команду под названием «Мост», которая является связующим звеном компании. Большинство других команд названы в честь чего-то случайного, например, птицы или мифологического существа. Идея состоит в том, чтобы каждый чувствовал себя частью Automattic, а не частью компании, принадлежащей Automattic. «Это помогает команде не слишком привязываться к тому, над чем они сейчас работают», — сказал Малленвег.В конце концов, миссия важнее всего.
Идея состоит в том, чтобы каждый чувствовал себя частью Automattic, а не частью компании, принадлежащей Automattic. «Это помогает команде не слишком привязываться к тому, над чем они сейчас работают», — сказал Малленвег.В конце концов, миссия важнее всего.
Титан
На данный момент немногие компании имеют большее влияние на работу Интернета, чем Automattic. И немногие люди, не названные Цукербергом, имеют большее влияние, чем Малленвег. Помимо всего этого «43% интернета», есть тот факт, что и WordPress, и Automattic в основном принадлежат ему. Когда Automattic продает акции новым инвесторам, все право голоса возвращается Мулленвегу. Когда он хочет подтолкнуть Automattic или WordPress в новом направлении, он старается делать это как можно мягче и совместными усилиями, но так или иначе обычно добивается своего.Мулленвег, как правило, склонен преуменьшать значение этого авторитета, отмечая, что пользователи всегда могут создать форк WordPress и заниматься своими делами, но нет никаких сомнений в том, что туда, куда идет Мулленвег, следует сообщество — и Интернет.
В общем, Мулленвег вряд ли можно назвать бьющим в грудь ученым мужем, но друзья и враги одинаково описывают убийцу, лежащего прямо под поверхностью. Его язвительность исторически относилась к тем, кто нарушал дух открытого программного обеспечения и открытых систем: например, за эти годы он несколько раз писал гневные блоги на создателя веб-сайтов Wix, последний раз отвечая на рекламную кампанию Wix.
называя свою закрытую бизнес-модель «как мотель для тараканов, где вы можете заселиться, но никогда не выписываться».Генеральный директор Wix Авишай Абраами не ответил на просьбу о комментариях, но написал собственный пост в блоге, опровергая многие утверждения Мулленвега. (Несколько лет назад, в ответ на другой гневный пост Малленвега, он написал еще один: «Вау, чувак, я даже не знал, что мы ссоримся».)
Анил Дэш, генеральный директор Glitch, ранее руководивший Six Apart и его платформой для блогов Movable Type, вспоминает, как Mullenweg извлекала выгоду из каждой ошибки Six Apart для развития WordPress. Дэш сказал, что не держит зла, и на самом деле отдает должное Мулленвегу за правильную стратегию в нужный момент, но есть одна вещь, которая его раздражает.«Хотел бы я, чтобы у него была такая энергия для Цука, — сказал Дэш, — а не для людей, которые у него были».
Дэш сказал, что не держит зла, и на самом деле отдает должное Мулленвегу за правильную стратегию в нужный момент, но есть одна вещь, которая его раздражает.«Хотел бы я, чтобы у него была такая энергия для Цука, — сказал Дэш, — а не для людей, которые у него были».
Вы можете возразить — и некоторые так и делают, — что в этот момент, когда мы оцениваем влияние технологий на нашу жизнь и общество, Мулленвег должен быть гораздо более громкой силой добра. Он не стесняется своих убеждений, но и не отстаивает их перед Конгрессом. Он мог бы разместить баннер «Facebook — это плохо» на каждом сайте WordPress в Интернете, но не сделал этого. Он не кричал во всеуслышание о проблеме дезинформации Facebook и не порицал системы сбора данных Google.Даже с точки зрения продукта WordPress имеет хорошие возможности для конкуренции с Substack, YouTube и многими другими. Несколько человек сказали мне, что Automattic оставляет миллиарды на столе и должна делать больше для производства и продвижения открытых альтернатив наиболее важным инструментам Интернета.
Купорос Мулленвега исторически предназначался для тех, кто нарушает дух открытого программного обеспечения и открытых систем.
Фото: Артуро Олмос для протокола
Технологическая индустрия сейчас переполнена злодеями и испытывает недостаток в героях, и Мулленвег прекрасно отвечает всем требованиям.У него есть тихое альтер-эго. Так где же суперкостюм?
Мулленвег на минуту задумался. «Я не знаю, с чего начать». Затем, после паузы: «Я действительно думаю, что вам нужно выбирать свои сражения, потому что вы не можете сражаться со всем сразу». Он обеспокоен тем, что изменение Facebook и Google требует изменения бизнес-модели Интернета, основанной на рекламе, что сложнее, чем кажется. Но в основном он считает вопросы конфиденциальности данных и модерации контента большими и сложными.«Я понимаю сложность модерации на Facebook», — сказал он. Да, Facebook должен работать лучше. Конечно. Но Малленвег, похоже, больше заинтересован в решении проблем, чем в поиске виноватых. «Мне действительно пришлось приложить сознательные усилия, чтобы держаться подальше от повседневных событий в новостях, — сказал он, — просто потому, что так много всего происходит».
Конечно. Но Малленвег, похоже, больше заинтересован в решении проблем, чем в поиске виноватых. «Мне действительно пришлось приложить сознательные усилия, чтобы держаться подальше от повседневных событий в новостях, — сказал он, — просто потому, что так много всего происходит».
Похоже, Малленвег никуда не торопится. Несмотря на то, что вокруг него крутится технологическая индустрия, с борьбой за регулирование, негативной реакцией в социальных сетях и, казалось бы, ежечасным изменением приоритетов, Мулленвег остается неуклонно верным курсу.«Мы стремимся создать уровень, на котором сможет работать любое другое веб-приложение», — сказал он. «Надеюсь, однажды 85% или 90% всех веб-сайтов будут использовать WordPress в качестве базового уровня». Прямо сейчас сеть работает в основном на закрытых платформах, принадлежащих таким компаниям, как Amazon и Facebook. «Но чтобы по-настоящему быть платформой, — сказал Малленвег, — она должна быть открытой. В противном случае это больше похоже на ловушку».
Он планирует провести остаток своей карьеры, создавая единственную настоящую веб-платформу, открытую систему, которой заслуживает Интернет.На что именно это похоже? Кто знает. Малленвег все больше увлекается Web3 и криптографией и видит в этом пространстве большую часть совместной работы и сообщества, которое ему нравится в WordPress и открытом исходном коде в целом. Он с гордостью напомнил мне, что WordPress.com начал принимать биткойны в 2012 году и что Виталик Бутерин, который в конечном итоге создал Ethereum,
написал об Automattic для журнала Bitcoin Magazine в том же году.
«Для меня Web3 воплощает в себе две основные идеи: децентрализацию и индивидуальную собственность», — сказал Мулленвег на
его недавняя ежегодная речь State of the Word, в которой он информирует сообщество WordPress о прошедшем году.Он предшествовал этому, сказав, что на самом деле не знает, как определить Web3 в данный момент — да кто знает? — но поддержал веру в интернет, который каждый может помочь создать, настроить в соответствии со своими потребностями и владеть собой, не платя арендную плату какому-то крупному технологическому гиганту. Тем не менее, он сделал предупреждение: «Для каждого проекта, который просит ваши деньги, доллары, чтобы вы заплатили стоимость дома за изображение обезьяны, вы должны спросить: применяются ли в нем те же свободы, что и сам WordPress? Насколько это применимо к расширению вашей свободы и свободы действий в мире?»
Тем не менее, он сделал предупреждение: «Для каждого проекта, который просит ваши деньги, доллары, чтобы вы заплатили стоимость дома за изображение обезьяны, вы должны спросить: применяются ли в нем те же свободы, что и сам WordPress? Насколько это применимо к расширению вашей свободы и свободы действий в мире?»
Детали действительно имеют значение, но это касается не только WordPress и определенно не только Automattic.Это всего лишь инструменты. Для него работа на протяжении всей жизни — это нечто гораздо большее, чем любой из них, даже больше, чем технологическая индустрия.
После того, как мы завершили наш первый звонок в Zoom, Малленвег прислал мне электронное письмо с темой: «Свобода превыше всего». Тело было цитатой Альбера Камю, которая работала как объяснение почти всего, во что Мулленвег верит, за что борется и над чем планирует посвятить остаток своей жизни: «Единственный способ справиться с несвободным миром — стать таким абсолютно свободен от того, что само ваше существование есть акт бунта. В письме было только это: имя Малленвег и три ссылки на сайты WordPress. Что еще нужно знать?
В письме было только это: имя Малленвег и три ссылки на сайты WordPress. Что еще нужно знать?
Обновление: эта история была обновлена, чтобы лучше прояснить разницу между Automattic, на котором работает WordPress.com, и программным обеспечением WordPress с открытым исходным кодом. Обновлено 21 декабря.
Elasticsearch Reference [1.7] | Elastic
Модуль снимков и восстановления позволяет создавать снимки отдельных
индексы или весь кластер в удаленный репозиторий, такой как общая файловая система,
S3 или HDFS.Эти снимки отлично подходят для резервного копирования, поскольку их можно восстановить.
относительно быстро, но они не являются архивными, потому что их можно восстановить только
к версиям Elasticsearch, которые могут читать индекс. Это означает, что:
- Моментальный снимок индекса, созданный в версии 2.x, можно восстановить в версии 5.x.
- Моментальный снимок индекса, созданный в версии 1.x, можно восстановить в версии 2. x.
- Моментальный снимок индекса, созданный в версии 1.x, может быть восстановлен в версии 5.x , а не .
 x.
x. Для восстановления моментального снимка индекса, созданного в 1.x до 5.x вы можете восстановить его до
кластер 2.x и использовать переиндексацию с удаленного сервера (доступно только в 5.0+) для перестроения
индекс в кластере 5.x. Это занимает столько же времени, сколько и восстановление из
архивные копии исходных данных.
Репозитории
Прежде чем можно будет выполнить любую операцию моментального снимка или восстановления, репозиторий моментальных снимков должен быть зарегистрирован в
Эластичный поиск. Настройки репозитория зависят от типа репозитория. Подробнее см. ниже.
ПОЛОЖИТЬ /_snapshot/my_backup
{
"тип": "фс",
"настройки": {
... специфические настройки репозитория...
}
} После регистрации репозитория информацию о нем можно получить с помощью следующей команды:
, которая возвращает:
{
"my_backup": {
"тип": "фс",
"настройки": {
"сжать": "истина",
"location": "/mount/backups/my_backup"
}
}
} Если имя репозитория не указано или в качестве имени репозитория используется _all , Elasticsearch вернет информацию о
все репозитории, зарегистрированные в настоящее время в кластере:
или
Репозиторий общей файловой системы
Репозиторий общей файловой системы ( "type": "fs" ) использует общую файловую систему для хранения моментальных снимков. Чтобы зарегистрироваться
Чтобы зарегистрироваться
общий репозиторий файловой системы необходимо смонтировать одну и ту же общую файловую систему в одно и то же место на всех
главные узлы и узлы данных. Это местоположение (или один из его родительских каталогов) должно быть зарегистрировано в path.repo .
настройка на всех мастер-узлах и узлах данных.
Предполагая, что общая файловая система смонтирована в /mount/backups/my_backup , необходимо добавить следующий параметр в
elasticsearch.yml файл:
path.repo: ["/mount/backups", "/mount/longterm_backups"]
Путь .Параметр репо поддерживает пути Microsoft Windows UNC, если в качестве имени указаны как минимум имя сервера и общий ресурс.
префикс и обратная косая черта правильно экранированы:
path.repo: ["\\\\MY_SERVER\\Snapshots"]
После перезапуска всех узлов можно использовать следующую команду для регистрации общего репозитория файловой системы в
имя my_backup :
$ curl -XPUT 'http://localhost:9200/_snapshot/my_backup' -d '{
"тип": "фс",
"настройки": {
"location": "/mount/backups/my_backup",
"сжать": правда
}
}' Если местоположение репозитория указано как относительный путь, этот путь будет разрешен по первому указанному пути
в пути .: репо
репо
$ curl -XPUT 'http://localhost:9200/_snapshot/my_backup' -d '{
"тип": "фс",
"настройки": {
"местоположение": "my_backup",
"сжать": правда
}
}' Поддерживаются следующие настройки:
| Расположение снимков. Обязательный. |
| Включает сжатие файлов моментальных снимков.Сжатие применяется только к файлам метаданных (сопоставление индекса и настройки). Файлы данных не сжимаются. По умолчанию |
| Большие файлы могут быть разбиты на куски во время моментального снимка, если это необходимо. Размер фрагмента может быть указан в байтах или |
 е. 1g, 10m, 5k. По умолчанию
е. 1g, 10m, 5k. По умолчанию Репозиторий URL-адресов только для чтения
Репозиторий URL-адресов ( "type": "url" ) можно использовать в качестве альтернативного способа доступа только для чтения к данным, созданным общим файлом.
системный репозиторий.URL-адрес, указанный в параметре url , должен
указывают на корень общего репозитория файловой системы. Поддерживаются следующие настройки:
| Расположение снимков. Обязательный. |
Репозиторий URL поддерживает следующие протоколы: «http», «https», «ftp», «file» и «jar». URL репозиториев с http: ,
https: и ftp: URL-адреса должны быть внесены в белый список, указав разрешенные URL-адреса в репозиториях . настройка. url.allowed_urls
url.allowed_urls
Этот параметр поддерживает подстановочные знаки вместо узла, пути, запроса и фрагмента. Например:
repositories.url.allowed_urls: ["http://www.example.org/root/*", "https://*.mydomain.com/*?*#*"]
репозиториев URL с файлом : URL-адреса могут указывать только на местоположения, зарегистрированные в настройке path.repo , аналогичной
общий репозиторий файловой системы.
Общие настройки репозитория
Ниже приведены общие настройки, применимые для всех типов репозиториев:
| Дроссели на скорость восстановления узла.По умолчанию |
| Дроссели на скорость моментальных снимков узла. |
 По умолчанию
По умолчанию Плагины репозитория
В этих официальных плагинах доступны другие серверные части репозитория:
Проверка репозитория
Когда репозиторий зарегистрирован, он сразу же проверяется на всех мастер-узлах и узлах данных, чтобы убедиться в его работоспособности.
на всех узлах, присутствующих в данный момент в кластере.Параметр Verify можно использовать для явного отключения репозитория.
проверка при регистрации или обновлении репозитория:
PUT /_snapshot/s3_repository?verify=false
{
"тип": "s3",
"настройки": {
"ведро": "my_s3_bucket",
"регион": "eu-west-1"
}
} Процесс проверки также можно выполнить вручную, выполнив следующую команду:
POST /_snapshot/my_backup/_verify
Возвращает список узлов, на которых репозиторий был успешно проверен, или сообщение об ошибке, если процесс проверки завершился неудачно.
Моментальный снимок
Репозиторий может содержать несколько моментальных снимков одного и того же кластера. Снимки идентифицируются уникальными именами в
Снимки идентифицируются уникальными именами в
кластер. Моментальный снимок с именем snapshot_1 в репозитории my_backup можно создать, выполнив следующие действия.
команда:
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
Параметр wait_for_completion указывает, должен ли запрос возвращаться сразу после снимка
инициализация (по умолчанию) или дождитесь завершения моментального снимка.Во время инициализации моментального снимка информация обо всех
предыдущие снэпшоты загружаются в память, а это значит, что в больших репозиториях это может занять несколько секунд (или
четные минуты) для возврата этой команды, даже если для параметра wait_for_completion установлено значение false .
По умолчанию создается снимок всех открытых и запущенных индексов в кластере. Это поведение можно изменить,
указание списка индексов в теле запроса моментального снимка.
ПОЛОЖИТЬ /_snapshot/my_backup/snapshot_1
{
"индексы": "индекс_1,индекс_2",
"игнорировать_недоступно": "истина",
"include_global_state": ложь
} Список индексов, которые должны быть включены в снимок, можно указать с помощью параметра индексы , который
поддерживает синтаксис с несколькими индексами. Запрос моментального снимка также поддерживает
Запрос моментального снимка также поддерживает
ignore_unavailable опция. Установка значения true приведет к тому, что несуществующие индексы будут игнорироваться во время моментального снимка.
творчество. По умолчанию, если параметр ignore_unavailable не установлен и индекс отсутствует, запрос моментального снимка завершится ошибкой.
Установив для include_global_state значение false, можно предотвратить сохранение глобального состояния кластера как части
снимок. По умолчанию весь моментальный снимок завершится ошибкой, если один или несколько индексов, участвующих в моментальном снимке, не имеют
доступны все первичные осколки.Это поведение можно изменить, установив частичное на истинное .
Процесс моментального снимка индекса является добавочным. В процессе создания снимка индекса Elasticsearch анализирует
список индексных файлов, которые уже хранятся в репозитории, и копирует только те файлы, которые были созданы или
изменилось с момента последнего снимка. Это позволяет сохранять несколько снимков в репозитории в компактном виде.
Это позволяет сохранять несколько снимков в репозитории в компактном виде.
Процесс создания снимков выполняется неблокирующим образом. Все операции индексации и поиска могут продолжать
выполняется для индекса, для которого создается моментальный снимок.Однако моментальный снимок представляет собой представление индекса на определенный момент времени.
в момент создания моментального снимка, поэтому записи, которые были добавлены в индекс после запуска процесса создания моментального снимка, отсутствуют.
будет присутствовать на снимке. Процесс моментального снимка запускается немедленно для запущенных основных сегментов.
и на данный момент не переезжают. Elasticsearch ждет
перемещение или инициализация осколков перед их созданием моментальных снимков.
Помимо создания копии каждого индекса, процесс моментального снимка может также хранить глобальные метаданные кластера, включая постоянные
настройки и шаблоны кластера.Временные настройки и зарегистрированные репозитории моментальных снимков не сохраняются как часть
снимок.
В каждый момент времени в кластере может выполняться только один процесс моментального снимка. Во время создания моментального снимка определенного сегмента
созданный этот осколок нельзя переместить на другой узел, что может помешать процессу ребалансировки и распределения
фильтрация. Elasticsearch сможет переместить осколок только на другой узел (в соответствии с текущим распределением
настройки фильтрации и алгоритм перебалансировки) после завершения моментального снимка.
После создания снимка информацию об этом снимке можно получить с помощью следующей команды:
GET /_snapshot/my_backup/snapshot_1
Все снимки, хранящиеся в настоящее время в репозитории, могут быть перечислены с помощью следующей команды:
GET /_snapshot /my_backup/_all
Снимок можно удалить из репозитория с помощью следующей команды:
DELETE /_snapshot/my_backup/snapshot_1
Когда снимок удаляется из репозитория, Elasticsearch удаляет все файлы, связанные с удаленным
снимок и не используется никакими другими снимками. Если операция удаления моментального снимка выполняется во время создания моментального снимка
Если операция удаления моментального снимка выполняется во время создания моментального снимка
создан, процесс создания моментального снимка будет прерван, и все файлы, созданные как часть процесса создания моментального снимка, будут удалены.
очищенный. Таким образом, операция удаления моментального снимка может использоваться для отмены длительных операций с моментальными снимками, которые были
начал по ошибке.
Репозиторий можно удалить с помощью следующей команды:
DELETE /_snapshot/my_backup
При удалении репозитория Elasticsearch удаляет только ссылку на место, где хранится репозиторий
снимки.Сами снимки остаются нетронутыми и на месте.
Восстановление
Моментальный снимок можно восстановить с помощью следующей команды:
POST /_snapshot/my_backup/snapshot_1/_restore
По умолчанию восстанавливаются все индексы в снимке, а также состояние кластера. Можно выбрать индексы, которые
должны быть восстановлены, а также предотвратить восстановление глобального состояния кластера с помощью индексов и
Параметры include_global_state в тексте запроса на восстановление. Список индексов поддерживает
Список индексов поддерживает
многоиндексный синтаксис. Параметры rename_pattern и rename_replacement также можно использовать для
переименуйте индекс при восстановлении, используя регулярное выражение, которое поддерживает ссылку на исходный текст, как объяснено
здесь.
Установите include_aliases на false , чтобы предотвратить восстановление псевдонимов вместе со связанными индексами
POST /_snapshot/my_backup/snapshot_1/_restore
{
"индексы": "индекс_1,индекс_2",
"игнорировать_недоступно": "истина",
"include_global_state": ложь,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
} Операция восстановления может быть выполнена на функционирующем кластере. Однако существующий индекс можно восстановить, только если он
закрыт и имеет то же количество осколков, что и индекс в моментальном снимке.
Операция восстановления автоматически открывает восстановленные индексы, если они были закрыты, и создает новые индексы, если они
в кластере не было. Если состояние кластера восстанавливается, восстановленные шаблоны, которые в данный момент не существуют в
Если состояние кластера восстанавливается, восстановленные шаблоны, которые в данный момент не существуют в
кластера, а существующие шаблоны с тем же именем заменяются восстановленными шаблонами.Восстановленный
постоянные настройки добавляются к существующим постоянным настройкам.
Частичное восстановление
По умолчанию вся операция восстановления завершается ошибкой, если один или несколько индексов, участвующих в операции, не имеют
снимки всех доступных осколков. Это может произойти, например, если не удалось сделать снимок некоторых осколков. Еще можно
восстановить такие индексы, установив частичное на истинное . Обратите внимание, что только успешно снятые осколки будут
восстанавливается в этом случае, и все отсутствующие осколки будут воссозданы пустыми.
Изменение параметров индекса во время восстановления
Большинство параметров индекса можно переопределить в процессе восстановления. Например, следующая команда восстановит
индекс index_1 без создания реплик при возврате к интервалу обновления по умолчанию:
POST /_snapshot/my_backup/snapshot_1/_restore
{
"индексы": "индекс_1",
"index_settings": {
"index. number_of_replicas": 0
},
"игнорировать_index_settings": [
"index.refresh_interval"
]
} 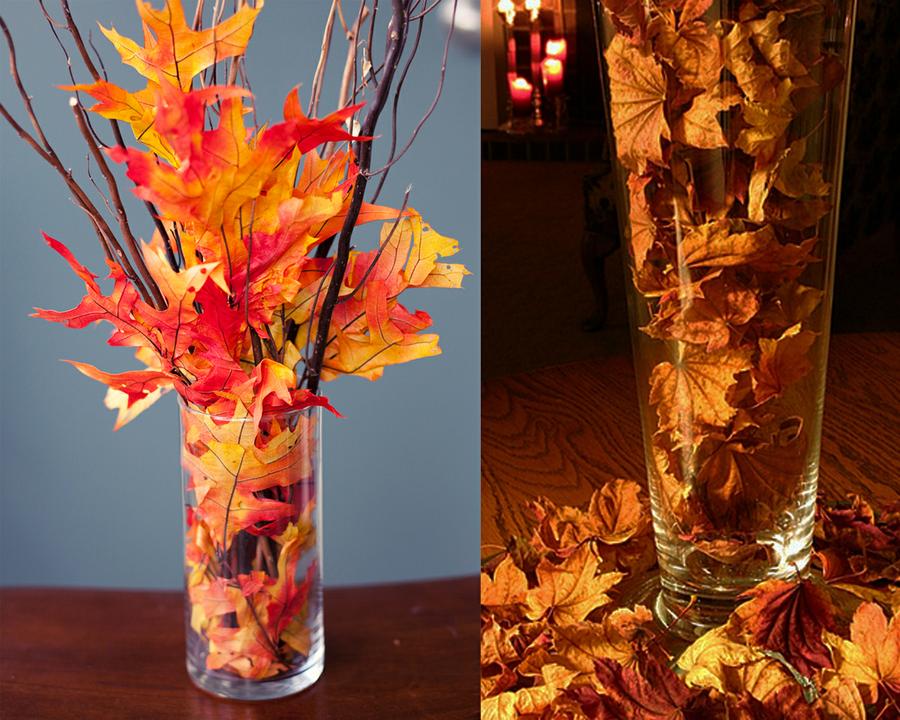 number_of_replicas": 0
},
"игнорировать_index_settings": [
"index.refresh_interval"
]
}
number_of_replicas": 0
},
"игнорировать_index_settings": [
"index.refresh_interval"
]
} Обратите внимание, что некоторые настройки, такие как index.number_of_shards нельзя изменить во время операции восстановления.
Восстановление в другой кластер
Информация, хранящаяся в моментальном снимке, не привязана к конкретному кластеру или имени кластера. Поэтому можно
восстановить снимок, сделанный из одного кластера, в другой кластер. Все, что требуется, это зарегистрировать репозиторий
содержащий моментальный снимок в новом кластере и запускающий процесс восстановления. Новый кластер не обязательно должен иметь
того же размера или топологии. Однако версия нового кластера должна быть такой же или более новой, чем версия кластера, который был
используется для создания моментального снимка.
Если новый кластер имеет меньший размер, необходимо принять дополнительные меры. В первую очередь необходимо убедиться
этот новый кластер имеет достаточную емкость для хранения всех индексов в моментальном снимке. Можно изменить настройки индексов
Можно изменить настройки индексов
во время восстановления, чтобы уменьшить количество реплик, что может помочь при восстановлении моментальных снимков в меньший кластер. Это также
можно выбрать только подмножество индексов, используя параметр индексов . До версии 1.5.0 elasticsearch
не проверял восстановленные постоянные настройки, что позволяет случайно восстановить несовместимый
открытие.zen.minimum_master_nodes , и в результате отключите меньший кластер до необходимого количества
добавлены основные подходящие узлы. Начиная с версии 1.5.0 несовместимые настройки игнорируются.
Если индексы в исходном кластере были назначены определенным узлам с помощью
фильтрации распределения сегментов, в новом кластере будут применяться те же правила. Следовательно
если новый кластер не содержит узлов с соответствующими атрибутами, на которых можно разместить восстановленный индекс, например
индекс не будет успешно восстановлен, если эти параметры выделения индекса не будут изменены во время операции восстановления.
Состояние моментального снимка
Список запущенных в данный момент моментальных снимков с подробной информацией об их состоянии можно получить с помощью следующей команды:
В этом формате команда вернет информацию обо всех запущенных в данный момент моментальных снимках. Указав имя репозитория, можно
чтобы ограничить результаты определенным репозиторием:
GET /_snapshot/my_backup/_status
Если указаны и имя репозитория, и идентификатор снимка, эта команда вернет подробную информацию о состоянии для данного снимка, даже
если он в данный момент не запущен:
GET /_snapshot/my_backup/snapshot_1/_status
Несколько идентификаторов также поддерживаются:
GET /_snapshot/my_backup/snapshot_1,snapshot_2/_status
Monitoring snapshot/restore progress
способы отслеживания хода создания моментального снимка и восстановления процессов во время их выполнения.Оба
операции поддерживают параметр
wait_for_completion , который блокирует клиент до завершения операции. Это
Это
самый простой метод, который можно использовать для получения уведомления о завершении операции.
Операцию моментального снимка также можно отслеживать с помощью периодических вызовов информации о моментальном снимке:
GET /_snapshot/my_backup/snapshot_1
Обратите внимание, что операция с информацией о моментальном снимке использует те же ресурсы и пул потоков, что и операция моментального снимка. Так,
выполнение операции с информацией о моментальном снимке во время создания моментальных снимков больших сегментов может привести к ожиданию операции с информацией о моментальном снимке.
для доступных ресурсов перед возвратом результата.На очень больших осколках время ожидания может быть значительным.
Для получения более оперативной и полной информации о моментальных снимках можно использовать команду состояния моментального снимка: возвращается
полная разбивка текущего состояния для каждого шарда, участвующего в снимке.
Процесс восстановления использует стандартный механизм восстановления Elasticsearch. В результате стандартное восстановление
В результате стандартное восстановление
службы мониторинга можно использовать для наблюдения за состоянием восстановления. При выполнении операции восстановления кластер
обычно переходит в состояние красный . Это происходит потому, что операция восстановления начинается с «восстановления» первичных осколков
восстановленные индексы. Во время этой операции основные осколки становятся недоступными, что проявляется в кластере red .
государство. После завершения восстановления основных сегментов Elasticsearch переключается на стандартный процесс репликации, который
создает необходимое количество реплик, в этот момент кластер переходит в состояние yellow .После того, как все необходимые реплики
создаются, кластер переключается в состояние зеленый .
Операция работоспособности кластера предоставляет только высокоуровневое состояние процесса восстановления. Можно получить больше
подробное представление о текущем состоянии процесса восстановления с помощью индексов восстановления и
API восстановления кошек.
Остановка текущих операций моментального снимка и восстановления
Инфраструктура моментального снимка и восстановления позволяет запускать только один моментальный снимок или одну операцию восстановления за раз.Если в настоящее время
текущий моментальный снимок был выполнен по ошибке или занимает необычно много времени, его можно прервать с помощью операции удаления моментального снимка.
Операция удаления моментального снимка проверяет, запущен ли удаленный моментальный снимок в данный момент, и если это так, операция удаления останавливается.
этот снимок перед удалением данных снимка из репозитория.
Операция восстановления использует стандартный механизм восстановления сегментов. Таким образом, любая выполняемая в данный момент операция восстановления может
отменить, удалив индексы, которые восстанавливаются.Обратите внимание, что данные по всем удаленным индексам будут удалены.
из кластера в результате этой операции.
Кибана | Шум
Публикация из оригинала Роя Бен-Альты https://aws. amazon.com/blogs/big-data/aws-big-data-analytics-sessions-at-reinvent-2017/
amazon.com/blogs/big-data/aws-big-data-analytics-sessions-at-reinvent-2017/
Нам не верится, что до re:Invent 2017 осталось всего несколько дней. Если вы примете участие в этом году, вам стоит посетить наши сеансы работы с большими данными! Категории «Большие данные» и «Машинное обучение» больше, чем когда-либо.Как и в предыдущие годы, вы можете найти эти сессии в различных направлениях, включая Аналитика и большие данные , Саммит по глубокому обучению , Искусственный интеллект и машинное обучение , Архитектура и Базы данных .
У нас проходят отличные сессии от таких организаций и компаний, как Vanguard, Cox Automotive, Pinterest, Netflix, FINRA, Amtrak, AmazonFresh, Sysco Foods, Twilio, American Heart Association, Expedia, Esri, Nextdoor и многих других.Все занятия записываются и выкладываются на YouTube. Кроме того, все слайды с сессий будут доступны на SlideShare.net после конференции.
В этом посте освещаются сеансы, которые будут представлены в рамках направления Analytics & Big Data , а также соответствующие сеансы других направлений, таких как Архитектура , Искусственный интеллект и машинное обучение и IoT . Если вас интересуют занятия по машинному обучению, не забудьте ознакомиться с нашим руководством по машинному обучению на сайте re:Invent 2017.
Если вас интересуют занятия по машинному обучению, не забудьте ознакомиться с нашим руководством по машинному обучению на сайте re:Invent 2017.
Каталог сессий этого года содержит следующие секционные сессии.
DAT201 — База данных и аналитика AWS, штат Союза — Четверг
Раджу Гулабани, вице-президент по базам данных, аналитике и искусственному интеллекту в AWS, расскажет об эволюции баз данных и аналитических сервисов в AWS, о новых базах данных и аналитических сервисах и функциях, которые мы запустили в этом году, а также о нашем видении дальнейших инноваций в этой области. Мы наблюдаем беспрецедентный рост объема собираемых данных в различных формах.Хранение, управление и анализ этих данных требуют служб баз данных, которые масштабируются и работают так, как раньше было невозможно. AWS предлагает набор баз данных и других сервисов данных, включая Amazon Aurora, Amazon DynamoDB, Amazon RDS, Amazon Redshift, Amazon ElastiCache, Amazon Kinesis и Amazon EMR, для обработки, хранения, управления и анализа данных. На этом занятии мы представляем обзор сервисов баз данных и аналитики AWS и обсуждаем, как клиенты используют эти сервисы сегодня.
На этом занятии мы представляем обзор сервисов баз данных и аналитики AWS и обсуждаем, как клиенты используют эти сервисы сегодня.
Глубокое изучение сценариев использования клиентами
ABD401 – Как Netflix отслеживает приложения в режиме, близком к реальному времени, с помощью Amazon Kinesis
Тысячи сервисов работают сообща, ежедневно доставляя миллионы часов видеопотоков клиентам Netflix.Эти приложения различаются по размеру, функциям и технологиям, но все они используют сеть Netflix для связи. Понимание взаимодействий между этими службами является сложной задачей как из-за огромного объема трафика, так и из-за динамического характера развертываний. На этом занятии мы сначала обсудим, почему Netflix выбрала Kinesis Streams для решения этих проблем в масштабе. Затем мы углубимся в то, как Netflix использует Kinesis Streams для обогащения журналов сетевого трафика и определения шаблонов использования в режиме реального времени. Наконец, мы расскажем, как Netflix использует эту систему для создания комплексных карт зависимостей, повышения эффективности сети и повышения отказоустойчивости. На этом занятии вы узнаете, как создать систему мониторинга приложений в режиме реального времени, используя журналы сетевого трафика, и получать полезную информацию в режиме реального времени.
Наконец, мы расскажем, как Netflix использует эту систему для создания комплексных карт зависимостей, повышения эффективности сети и повышения отказоустойчивости. На этом занятии вы узнаете, как создать систему мониторинга приложений в режиме реального времени, используя журналы сетевого трафика, и получать полезную информацию в режиме реального времени.
SRV319 – Как компания Nextdoor построила масштабируемый бессерверный конвейер данных для миллиардов событий в день
В этом сеансе вы узнаете, как компания Nextdoor заменила собственный конвейер данных, основанный на топологии узлов Flume, полностью бессерверной архитектурой на основе Kinesis и Lambda.Внеся эти изменения, они повысили как надежность своих данных, так и время доставки миллиардов записей данных в озеро данных на базе Amazon S3 и кластер Amazon Redshift. Nextdoor — это частная социальная сеть для жителей района.
ABD205 – Взять страницу из книги Ivy Tech: использование данных для успеха учащихся
Данные говорят. Узнайте, как Ivy Tech, крупнейший в стране общественный колледж с единой аккредитацией, использует AWS для сбора, анализа данных о поведении учащихся и принятия соответствующих мер на благо более 3100 учащихся.На этом занятии описывается процесс от зарождения до реализации в штате Индиана и рассказывается, как модель Ivy Tech можно применить к вашим собственным сложным бизнес-задачам.
Узнайте, как Ivy Tech, крупнейший в стране общественный колледж с единой аккредитацией, использует AWS для сбора, анализа данных о поведении учащихся и принятия соответствующих мер на благо более 3100 учащихся.На этом занятии описывается процесс от зарождения до реализации в штате Индиана и рассказывается, как модель Ivy Tech можно применить к вашим собственным сложным бизнес-задачам.
ABD207 – Использование AWS для борьбы с финансовыми преступлениями и защиты национальной безопасности
Известно, что банки не обмениваются данными и не сотрудничают друг с другом. Но именно это и делает Коалиция средних банков Америки (MBCA) для борьбы с цифровыми финансовыми преступлениями и защиты национальной безопасности.Используя облако AWS, MBCA разработала общую утилиту для анализа данных, которая обрабатывает терабайты неконкурентных данных об учетных записях клиентов, транзакциях и государственных рисках. Интеллектуальные данные, полученные на основе данных, помогают банкам повышать эффективность своих операций, сокращать затраты на рабочую силу и эксплуатационные расходы, а также уменьшать объемы ложных срабатываний. Коллективный разум также позволяет усилить соблюдение правил по борьбе с отмыванием денег (AML), помогая участникам выявлять внутренние риски и, в первую очередь, определять проблемы, связанные с обнаружением этих рисков.На этом занятии демонстрируется, как облако AWS поддерживает MBCA для предоставления расширенной аналитики данных, предоставления согласованных операционных моделей для финансовых учреждений, снижения затрат и укрепления национальной безопасности.
Коллективный разум также позволяет усилить соблюдение правил по борьбе с отмыванием денег (AML), помогая участникам выявлять внутренние риски и, в первую очередь, определять проблемы, связанные с обнаружением этих рисков.На этом занятии демонстрируется, как облако AWS поддерживает MBCA для предоставления расширенной аналитики данных, предоставления согласованных операционных моделей для финансовых учреждений, снижения затрат и укрепления национальной безопасности.
ABD208 – Cox Automotive расширяет возможности масштабирования с помощью Splunk Cloud и AWS и исследует новые инновации с помощью Amazon Kinesis Firehose практически мгновенный MTTI, сократить количество инцидентов на аукционах на 90 % и заранее прогнозировать сбои.Мы также представляем долгожданную возможность, которая позволяет вам получать, преобразовывать и анализировать данные в режиме реального времени с помощью Splunk и Amazon Kinesis Firehose, чтобы получать ценную информацию из ваших облачных ресурсов. Теперь получить доступ к мониторингу инфраструктуры на основе аналитики с помощью Splunk Enterprise и Splunk Cloud стало проще и быстрее, чем когда-либо.
Теперь получить доступ к мониторингу инфраструктуры на основе аналитики с помощью Splunk Enterprise и Splunk Cloud стало проще и быстрее, чем когда-либо.
ABD209 – Увеличение скорости инноваций с помощью Центра данных и аналитики данных в компании Takeda
Исторически сложилось так, что разрозненность данных, аналитики и процессов в разных функциях, на разных этапах разработки и в разных регионах создавала препятствия для эффективности НИОКР.Сбор правильных данных, необходимых для принятия решений, был сложной задачей из-за проблем доступности, доверия и своевременности. На этом занятии вы узнаете, как Takeda претерпевает преобразования в области исследований и разработок, чтобы ускорить вывод на рынок высокоэффективных методов лечения для улучшения жизни пациентов. Центр данных и аналитики был создан совместно с Deloitte для решения этих проблем и поддержки эффективного получения аналитических данных для таких функций, как клинические операции, клинические разработки, медицинские дела, управление портфелем и финансирование НИОКР. В озере данных, размещенном на AWS, эти данные обрабатываются, интегрируются и предоставляются конечным бизнес-пользователям через интерфейсы визуализации данных, а специалистам по данным — через прямое подключение. Узнайте, как компания Takeda добилась значительного сокращения времени — с недель до минут — на сбор и предоставление данных, которые потенциально могут сократить время цикла разработки лекарств. Концентратор также обеспечивает более эффективные операции и согласование для достижения целей продукта за счет межфункциональной командной ответственности и совместной работы благодаря возможности доступа к одним и тем же междоменным данным.
В озере данных, размещенном на AWS, эти данные обрабатываются, интегрируются и предоставляются конечным бизнес-пользователям через интерфейсы визуализации данных, а специалистам по данным — через прямое подключение. Узнайте, как компания Takeda добилась значительного сокращения времени — с недель до минут — на сбор и предоставление данных, которые потенциально могут сократить время цикла разработки лекарств. Концентратор также обеспечивает более эффективные операции и согласование для достижения целей продукта за счет межфункциональной командной ответственности и совместной работы благодаря возможности доступа к одним и тем же междоменным данным.
ABD210 – Модернизация Amtrak: бессерверное решение для передачи данных в режиме реального времени
Будучи единственным в стране оператором высокоскоростных междугородных пассажирских поездов, Amtrak должна знать критически важную информацию для ведения своего бизнеса, например: время? Как меняются заказы и доходы? Amtrak столкнулась с непредсказуемым и часто медленным временем отклика от существующих баз данных, которое колебалось от секунд до часов; существующие информационные панели бронирования и доходов были основаны на электронных таблицах и заполнялись вручную; несколько копий данных хранились в разных репозиториях без интеграции и непротиворечивости; а затраты на эксплуатацию и техническое обслуживание (O&M) были относительно высокими. Присоединяйтесь к нам, чтобы продемонстрировать, как Deloitte и Amtrak успешно внедрили облачную операционную базу данных и аналитическую витрину данных для отчетности почти в реальном времени менее чем за шесть месяцев. Мы выделяем конкретные проблемы и модернизацию архитектуры собственного решения AWS «Платформа как услуга» (PaaS). Решение включает в себя облачные компоненты, такие как AWS Lambda для микросервисов, Amazon Kinesis и AWS Data Pipeline для перемещения данных, Amazon S3 для хранения, Amazon DynamoDB для управляемой службы баз данных NoSQL и Amazon Redshift для отчетов и информационных панелей в режиме, близком к реальному времени.Решение Deloitte позволило обрабатывать «в масштабе» 1 миллион транзакций в день и до 2 тысяч транзакций в минуту. Он обеспечивает гибкость и масштабируемость, в значительной степени устраняет необходимость в управлении системой и значительно снижает эксплуатационные расходы. Кроме того, он заложил основу для вывода из эксплуатации устаревших систем, что, как ожидается, позволит сэкономить не менее 1 миллиона долларов в течение 3 лет.
Присоединяйтесь к нам, чтобы продемонстрировать, как Deloitte и Amtrak успешно внедрили облачную операционную базу данных и аналитическую витрину данных для отчетности почти в реальном времени менее чем за шесть месяцев. Мы выделяем конкретные проблемы и модернизацию архитектуры собственного решения AWS «Платформа как услуга» (PaaS). Решение включает в себя облачные компоненты, такие как AWS Lambda для микросервисов, Amazon Kinesis и AWS Data Pipeline для перемещения данных, Amazon S3 для хранения, Amazon DynamoDB для управляемой службы баз данных NoSQL и Amazon Redshift для отчетов и информационных панелей в режиме, близком к реальному времени.Решение Deloitte позволило обрабатывать «в масштабе» 1 миллион транзакций в день и до 2 тысяч транзакций в минуту. Он обеспечивает гибкость и масштабируемость, в значительной степени устраняет необходимость в управлении системой и значительно снижает эксплуатационные расходы. Кроме того, он заложил основу для вывода из эксплуатации устаревших систем, что, как ожидается, позволит сэкономить не менее 1 миллиона долларов в течение 3 лет.
ABD211 – Sysco Foods: путь от слишком большого количества данных к проверенным аналитическим данным
Для этого Sysco перешла с нескольких хранилищ данных на экосистему AWS, включая Amazon Redshift, Amazon EMR, AWS Data Pipeline и другие. Когда команда Sysco работала с Tableau, они получили гибкую информацию о своем бизнесе. Узнайте, как Sysco решила использовать AWS, как они масштабировались и как они стали более стратегическими благодаря экосистеме AWS и Tableau.
ABD217 — От пакетной обработки к потоковой: как Amazon Flex использует аналитику в реальном времени для своевременной доставки пакетов изучить преимущества потоковой аналитики.Узнайте о передовых методах расширения вашей архитектуры от хранилищ данных и баз данных до решений, работающих в режиме реального времени. Узнайте, как использовать Amazon Kinesis для получения аналитических данных в режиме реального времени и их интеграции с Amazon Aurora, Amazon RDS, Amazon Redshift и Amazon S3. Команда Amazon Flex описывает, как они использовали потоковую аналитику в своем мобильном приложении Amazon Flex, используемую водителями службы доставки Amazon, чтобы ежемесячно доставлять миллионы посылок вовремя. Они обсуждают архитектуру, позволившую перейти от системы пакетной обработки к системе реального времени, решить проблемы переноса существующих пакетных данных в потоковые данные и узнать, как извлечь выгоду из аналитики в реальном времени.
Команда Amazon Flex описывает, как они использовали потоковую аналитику в своем мобильном приложении Amazon Flex, используемую водителями службы доставки Amazon, чтобы ежемесячно доставлять миллионы посылок вовремя. Они обсуждают архитектуру, позволившую перейти от системы пакетной обработки к системе реального времени, решить проблемы переноса существующих пакетных данных в потоковые данные и узнать, как извлечь выгоду из аналитики в реальном времени.
ABD218 – Как баскетбольная Евролига использует аналитику Интернета вещей для привлечения болельщиков отраслей, включая средства массовой информации, развлечения и спорт. Низкая стоимость и простота внедрения аналитических сервисов AWS и AWS IoT позволили AGT, лидеру в области IoT, разработать свою аналитическую платформу IoTA.Используя IoTA, AGT представила Баскетбольной Евролиге специальное решение для производства контента в режиме реального времени и взаимодействия с болельщиками в сезоне 2017–18. На этом занятии мы подробно рассмотрим, как спроектировано это решение для безопасного, масштабируемого и высокопроизводительного сбора данных от спортсменов, тренеров и болельщиков. Мы также говорим о том, как данные преобразуются в идеи и интегрируются в конвейер генерации контента. Наконец, мы демонстрируем, как это решение может быть легко адаптировано для других отраслей и приложений.
На этом занятии мы подробно рассмотрим, как спроектировано это решение для безопасного, масштабируемого и высокопроизводительного сбора данных от спортсменов, тренеров и болельщиков. Мы также говорим о том, как данные преобразуются в идеи и интегрируются в конвейер генерации контента. Наконец, мы демонстрируем, как это решение может быть легко адаптировано для других отраслей и приложений.
ABD222 – Как уверенно использовать данные для удовлетворения потребностей всей вашей организации
Где вы находитесь в спектре ИТ-лидеров? Уверены ли вы, что предоставляете технологии и решения, которые постоянно удовлетворяют или превосходят потребности ваших внутренних клиентов? Считают ли ваши коллеги за исполнительным столом вас лидером инновационных технологий? Инновационные ИТ-лидеры понимают ценность передачи данных и аналитики непосредственно в руки лиц, принимающих решения, и в свои собственные.На этой сессии Дарен Тейн, технический директор Domo, расскажет, как новаторские ИТ-лидеры помогают изменить культуру в своих организациях. Посмотрите, насколько преобразующим может быть доступ в режиме реального времени ко всем данным, которые имеют отношение к ВАШЕЙ работе (включая полное представление всей вашей среды AWS), а также поймите, как это может помочь вам стать лидером в применении такая же схема во всей вашей компании
Посмотрите, насколько преобразующим может быть доступ в режиме реального времени ко всем данным, которые имеют отношение к ВАШЕЙ работе (включая полное представление всей вашей среды AWS), а также поймите, как это может помочь вам стать лидером в применении такая же схема во всей вашей компании
ABD303 – Разработка аналитической платформы – Путь Sysco от разрозненных систем к озеру данных и далее
Sysco имеет около 200 действующих компаний по различным направлениям бизнеса в США, Канаде, Центральной/Южной Америке и Европе.Являясь мировым лидером в сфере общественного питания, Sysco определила необходимость рационализации сбора, преобразования и представления данных, полученных от распределенных подразделений и систем, в централизованную экосистему данных. Группа бизнес-аналитики и аналитики Sysco выполнила эти требования, создав озеро данных с масштабируемой аналитикой и механизмами запросов, использующими сервисы AWS. На этой сессии Sysco расскажет о своем пути от компании, ориентированной на ретроспективную отчетность, к организации, ориентированной на аналитику. Они расскажут об архитектуре решения, проблемах и уроках, извлеченных из развертывания платформы самообслуживания. Они также расскажут об используемых ими шаблонах проектирования и о том, как они разработали решение для прогнозной аналитики с использованием Amazon Redshift Spectrum, Amazon S3, Amazon EMR, AWS Glue, Amazon Elasticsearch Service и других сервисов AWS.
Они расскажут об архитектуре решения, проблемах и уроках, извлеченных из развертывания платформы самообслуживания. Они также расскажут об используемых ими шаблонах проектирования и о том, как они разработали решение для прогнозной аналитики с использованием Amazon Redshift Spectrum, Amazon S3, Amazon EMR, AWS Glue, Amazon Elasticsearch Service и других сервисов AWS.
ABD309 – Как Twilio масштабирует свою культуру, основанную на данных
Являясь ведущей облачной коммуникационной платформой, Twilio всегда сильно ориентировалась на данные.Но по мере того, как численность персонала и объемы данных росли — и росли быстро — они столкнулись со многими новыми проблемами. Одноразовые статические отчеты работают, когда вы небольшой стартап, но как вы поддерживаете компанию в стадии роста на пути к успешному IPO и далее? Сегодня группа обработки данных Twilio использует AWS и Looker для предоставления доступа к данным 700 коллегам. У отделов есть данные, необходимые им для принятия решений, а облачное масштабирование означает, что они быстро получают ответы. Данные обеспечивают реальную ценность для бизнеса в Twilio, предоставляя 360-градусное представление о своих клиентах, продуктах и бизнесе.На этом занятии вы услышите истории из первых уст непосредственно от команды обработки данных Twilio и узнаете реальные советы по развитию культуры, основанной на данных, в масштабе.
Данные обеспечивают реальную ценность для бизнеса в Twilio, предоставляя 360-градусное представление о своих клиентах, продуктах и бизнесе.На этом занятии вы услышите истории из первых уст непосредственно от команды обработки данных Twilio и узнаете реальные советы по развитию культуры, основанной на данных, в масштабе.
ABD310 – Как FINRA обеспечивает безопасность своей платформы больших данных и анализа данных на AWS
FINRA использует технологии обработки больших данных и анализа данных для выявления мошенничества, манипулирования рынком и инсайдерской торговли на рынках капитала США. Являясь финансовым регулятором, FINRA анализирует крайне конфиденциальные данные, поэтому информационная безопасность имеет решающее значение.Узнайте, как FINRA защищает свое озеро данных Amazon S3 и свою платформу обработки данных на Amazon EMR и Amazon Redshift, а также предоставляет специалистам по данным инструменты, необходимые им для эффективной работы. Кроме того, FINRA делится передовыми практиками безопасности AWS, охватывая такие темы, как обновления AMI, микросегментация, шифрование, управление ключами, ведение журналов, управление идентификацией и доступом, а также соответствие требованиям.
Кроме того, FINRA делится передовыми практиками безопасности AWS, охватывая такие темы, как обновления AMI, микросегментация, шифрование, управление ключами, ведение журналов, управление идентификацией и доступом, а также соответствие требованиям.
ABD331 – Log Analytics в Expedia с использованием Amazon Elasticsearch Service
Expedia использует Amazon Elasticsearch Service (Amazon ES) для различных критически важных задач, от агрегации журналов до мониторинга приложений и оптимизации цен.На этом занятии команда Expedia расскажет, как они используют Amazon ES и Kibana для анализа и визуализации журналов запуска Docker, данных AWS CloudTrail и показателей приложений. Они делятся передовыми методами разработки масштабируемого и безопасного решения для анализа журналов с помощью Amazon ES, поэтому вы можете практически без усилий добавлять новые источники данных и быстро получать ценную информацию
.
ABD316 – Американская кардиологическая ассоциация: поиск лекарств от сердечных заболеваний с помощью технологий
Объединение разрозненных наборов данных и обеспечение их доступности для специалистов по данным и исследователей является распространенной проблемой для многих организаций, не только в сфере исследований в области здравоохранения. Американская кардиологическая ассоциация (AHA) создала платформу для обработки данных с использованием Amazon EMR, Amazon Elasticsearch Service и других сервисов AWS, которая собирает несколько наборов данных и позволяет проводить расширенные исследования наборов данных фенотипа и генотипа, направленные на лечение сердечных заболеваний. В этой сессии мы представляем, как AHA построила эту платформу, и основные проблемы, которые они решили с помощью решения. Мы также предоставляем демонстрацию платформы и оставляем вам предложения и дальнейшие шаги, чтобы вы могли создавать аналогичные решения для своих вариантов использования
Американская кардиологическая ассоциация (AHA) создала платформу для обработки данных с использованием Amazon EMR, Amazon Elasticsearch Service и других сервисов AWS, которая собирает несколько наборов данных и позволяет проводить расширенные исследования наборов данных фенотипа и генотипа, направленные на лечение сердечных заболеваний. В этой сессии мы представляем, как AHA построила эту платформу, и основные проблемы, которые они решили с помощью решения. Мы также предоставляем демонстрацию платформы и оставляем вам предложения и дальнейшие шаги, чтобы вы могли создавать аналогичные решения для своих вариантов использования
.
ABD319 – Инструменты для повышения эффективности: DIY Solutions @ Netflix
В Netflix мы традиционно подходим к эффективности облачных вычислений с человеческой точки зрения, будь то личные встречи с крупнейшими сервисными командами или ручное резервирование.Со временем мы поняли, что эти ручные процессы не масштабируются, поскольку бизнес продолжает расти. Поэтому в прошлом году мы сосредоточились на создании инструментов, которые позволяют нам принимать более проницательные решения, основанные на данных, в отношении емкости и эффективности. На этом занятии мы обсудим самодельные приложения, информационные панели и процессы, которые мы создали, чтобы повысить производительность и эффективность. Мы начинаем с точки зрения десяти тысяч футов, чтобы понять уникальные проблемы бизнеса и облачных вычислений, которые побудили нас создать эти продукты, и обсудить детали реализации, включая проблемы, с которыми мы столкнулись на этом пути.Обсуждаемые инструменты включают Picsou, преемника нашего анализатора стоимости файла биллинга AWS; Libra, простое в использовании приложение для конвертации бронирований; и информационные панели затрат и эффективности, которые передают полезный финансовый контекст более чем 50 инженерным командам и менеджерам.
Поэтому в прошлом году мы сосредоточились на создании инструментов, которые позволяют нам принимать более проницательные решения, основанные на данных, в отношении емкости и эффективности. На этом занятии мы обсудим самодельные приложения, информационные панели и процессы, которые мы создали, чтобы повысить производительность и эффективность. Мы начинаем с точки зрения десяти тысяч футов, чтобы понять уникальные проблемы бизнеса и облачных вычислений, которые побудили нас создать эти продукты, и обсудить детали реализации, включая проблемы, с которыми мы столкнулись на этом пути.Обсуждаемые инструменты включают Picsou, преемника нашего анализатора стоимости файла биллинга AWS; Libra, простое в использовании приложение для конвертации бронирований; и информационные панели затрат и эффективности, которые передают полезный финансовый контекст более чем 50 инженерным командам и менеджерам.
ABD312 – Глубокое погружение: перенос рабочих нагрузок больших данных на AWS
Клиенты переносят свои рабочие нагрузки по аналитике, обработке данных (ETL) и науке о данных, работающие на устройствах Apache Hadoop, Spark и хранилищах данных, с локальных развертываний на AWS, чтобы сократить расходы, повысить доступность и повысить производительность. AWS предлагает широкий набор аналитических сервисов, включая решения для пакетной обработки, потоковой обработки, машинного обучения, оркестровки рабочих процессов данных и хранения данных. На этом занятии основное внимание будет уделено определению компонентов и рабочих процессов в вашей текущей среде; а также рекомендации по переносу этих рабочих нагрузок в подходящий продукт AWS для анализа данных. Мы рассмотрим такие сервисы, как Amazon EMR, Amazon Athena, Amazon Redshift, Amazon Kinesis и другие. Мы также представим Vanguard, американскую компанию по управлению инвестициями, базирующуюся в Малверне, штат Пенсильвания, с более чем 4 долларами.4 трлн активов под управлением. Ритеш Шах, старший руководитель программы облачной аналитики в Vanguard, расскажет, как они организовали миграцию на сервисы аналитики AWS, включая рабочие нагрузки Hadoop и Spark, на Amazon EMR. Ритеш расскажет о технических проблемах, с которыми они столкнулись и которые они преодолели, а также поделится общими рекомендациями и советами по настройке, чтобы ускорить время запуска в производство.
AWS предлагает широкий набор аналитических сервисов, включая решения для пакетной обработки, потоковой обработки, машинного обучения, оркестровки рабочих процессов данных и хранения данных. На этом занятии основное внимание будет уделено определению компонентов и рабочих процессов в вашей текущей среде; а также рекомендации по переносу этих рабочих нагрузок в подходящий продукт AWS для анализа данных. Мы рассмотрим такие сервисы, как Amazon EMR, Amazon Athena, Amazon Redshift, Amazon Kinesis и другие. Мы также представим Vanguard, американскую компанию по управлению инвестициями, базирующуюся в Малверне, штат Пенсильвания, с более чем 4 долларами.4 трлн активов под управлением. Ритеш Шах, старший руководитель программы облачной аналитики в Vanguard, расскажет, как они организовали миграцию на сервисы аналитики AWS, включая рабочие нагрузки Hadoop и Spark, на Amazon EMR. Ритеш расскажет о технических проблемах, с которыми они столкнулись и которые они преодолели, а также поделится общими рекомендациями и советами по настройке, чтобы ускорить время запуска в производство.
ABD402 – Как Esri оптимизирует массивные архивы изображений для аналитики в облаке
Объем петабайтных архивов изображений со спутников, самолетов и дронов продолжает расти в геометрической прогрессии.В основном они существуют в виде частично структурированных данных, но они представляют ценность только при доступе и обработке широким спектром продуктов как для визуализации, так и для анализа. В этом сеансе представлен обзор того, как ArcGIS индексирует и структурирует данные, чтобы к любой их части можно было быстро получить доступ, обработать и проанализировать путем чтения только минимального объема данных, необходимого для задачи. На этом занятии мы поделимся передовыми методами структурирования и сжатия массивных наборов данных в Amazon S3, чтобы их можно было эффективно анализировать.Мы также рассматриваем ряд различных форматов изображений, в том числе GeoTIFF (используемый для программы Public Datasets on AWS, Landsat на AWS), оптимизированный для облака GeoTIFF, MRF и CRF, а также различные подходы к сжатию, чтобы показать влияние на производительность обработки. Наконец, мы приводим примеры того, как эта технология использовалась для помощи в обработке изображений и анализе реакции на ураган Харви.
Наконец, мы приводим примеры того, как эта технология использовалась для помощи в обработке изображений и анализе реакции на ураган Харви.
ABD329 – Заглянуть внутрь – как Amazon.com использует сервисы AWS для аналитики в больших масштабах поддержка бизнеса.На этом занятии мы поговорим о том, как Amazon.com использует технологии AWS для создания масштабируемой среды для данных и аналитики. Мы рассмотрим, как Amazon развивает мир хранилищ данных, сочетая озеро данных и параллельные масштабируемые вычислительные механизмы, такие как Amazon EMR и Amazon Redshift.
ABD327 – Миграция традиционного хранилища данных в современное озеро данных
На этом занятии мы обсудим новейшие функции Amazon Redshift и Redshift Spectrum, а также подробно рассмотрим их архитектуру и внутреннюю работу.Мы рассказываем о многих последних улучшениях доступности, производительности и управления, а также о том, как они улучшают работу конечных пользователей. Вы также услышите мнение компании 21st Century Fox, которая представляет пример быстрого перехода с локального хранилища данных на Amazon Redshift. Узнайте, как они расширяют свое хранилище данных до озера данных, которое охватывает несколько источников данных и форматов данных. Эта архитектура помогает им связать воедино разрозненные бизнес-подразделения и получить полезную 360-градусную информацию о своей потребительской базе.
Вы также услышите мнение компании 21st Century Fox, которая представляет пример быстрого перехода с локального хранилища данных на Amazon Redshift. Узнайте, как они расширяют свое хранилище данных до озера данных, которое охватывает несколько источников данных и форматов данных. Эта архитектура помогает им связать воедино разрозненные бизнес-подразделения и получить полезную 360-градусную информацию о своей потребительской базе.
MCL202 – Ally Bank & Cognizant: изменение качества обслуживания клиентов с помощью Amazon Alexa
Учитывая растущую популярность интерфейсов на естественном языке, таких как технология Voice as User или искусственный интеллект (AI), Ally® Bank искал взаимодействовать с клиентами, обеспечивая прямые транзакции посредством разговора или голоса. Им также необходимо было разработать возможность, позволяющую третьим сторонам безопасно подключаться к банку для обмена и обмена информацией с использованием протокола аутентификации oAuth, который рассматривается как будущее безопасных банковских технологий. Команда Cognizant по архитектуре в партнерстве с группой по архитектуре предприятий Ally Bank определила правильный продукт для интеграции oAuth с Amazon Alexa и сторонними технологиями. На этом занятии мы обсудим, как создание продуктов с помощью диалогового ИИ помогает Ally Bank предлагать клиентам инновационное обслуживание; увеличить удержание за счет улучшенной персонализации на основе данных; повысить эффективность и удобство обслуживания клиентов; и получить глубокое представление о потребностях клиентов с помощью анализа данных и прогнозной аналитики, чтобы предлагать новые продукты и услуги.
Команда Cognizant по архитектуре в партнерстве с группой по архитектуре предприятий Ally Bank определила правильный продукт для интеграции oAuth с Amazon Alexa и сторонними технологиями. На этом занятии мы обсудим, как создание продуктов с помощью диалогового ИИ помогает Ally Bank предлагать клиентам инновационное обслуживание; увеличить удержание за счет улучшенной персонализации на основе данных; повысить эффективность и удобство обслуживания клиентов; и получить глубокое представление о потребностях клиентов с помощью анализа данных и прогнозной аналитики, чтобы предлагать новые продукты и услуги.
MCL317 – Организация обучения машинному обучению для рекомендаций Netflix
В Netflix мы широко используем алгоритмы машинного обучения (ML), чтобы рекомендовать подходящие названия более чем 100 миллионам наших пользователей на основе их вкусов. Все на домашней странице участника основано на фактических данных и проверено A / B, и мы внедряем его на основе моделей машинного обучения. Эти модели обучаются с помощью Meson, нашей системы оркестровки рабочих процессов. Meson отличается от других механизмов рабочего процесса тем, что обрабатывает более сложные графы выполнения, такие как циклы и параметризованные разветвления.Meson может планировать задания Spark, контейнеры Docker, сценарии bash, код Scala и многое другое. Meson также предоставляет богатый визуальный интерфейс для мониторинга активных рабочих процессов и проверки журналов выполнения. Он имеет мощный Scala DSL для создания рабочих процессов, а также REST API. На этом занятии мы сосредоточимся на том, как Meson обучает рекомендательные модели машинного обучения в производственной среде, и на том, как мы реконструировали ее для масштабирования с учетом растущей потребности в широких приложениях ETL в Netflix. В качестве движущей силы для этого изменения нам пришлось разработать уровень сохраняемости для Meson.Мы рассказываем о том, как мы перешли с Cassandra на Amazon RDS с поддержкой Amazon Aurora
Эти модели обучаются с помощью Meson, нашей системы оркестровки рабочих процессов. Meson отличается от других механизмов рабочего процесса тем, что обрабатывает более сложные графы выполнения, такие как циклы и параметризованные разветвления.Meson может планировать задания Spark, контейнеры Docker, сценарии bash, код Scala и многое другое. Meson также предоставляет богатый визуальный интерфейс для мониторинга активных рабочих процессов и проверки журналов выполнения. Он имеет мощный Scala DSL для создания рабочих процессов, а также REST API. На этом занятии мы сосредоточимся на том, как Meson обучает рекомендательные модели машинного обучения в производственной среде, и на том, как мы реконструировали ее для масштабирования с учетом растущей потребности в широких приложениях ETL в Netflix. В качестве движущей силы для этого изменения нам пришлось разработать уровень сохраняемости для Meson.Мы рассказываем о том, как мы перешли с Cassandra на Amazon RDS с поддержкой Amazon Aurora
.
MCL350 – Люди против машин: как Pinterest использует сообщество рабочих Amazon Mechanical Turk для улучшения машинного обучения В технологическом секторе краудсорсинг играет важную роль в проверке алгоритмов машинного обучения, что, в свою очередь, улучшает взаимодействие с пользователем. На этом занятии мы исследуем, как Pinterest адаптировался к повышенной надежности человеческой оценки для улучшения своего продукта, уделяя особое внимание тому, как они интегрировались с платформой Mechanical Turk. Эта презентация предназначена для инженеров, аналитиков, менеджеров программ и менеджеров по продуктам, которые заинтересованы в том, как компании полагаются на платформу человеческой оценки Mechanical Turk для лучшего понимания контента и улучшения алгоритмов машинного обучения. Обсуждение сосредоточено на анализе и продуктовых решениях, связанных с созданием высококачественной системы краудсорсинга, которая использует преимущества мощного рабочего сообщества Mechanical Turk.
На этом занятии мы исследуем, как Pinterest адаптировался к повышенной надежности человеческой оценки для улучшения своего продукта, уделяя особое внимание тому, как они интегрировались с платформой Mechanical Turk. Эта презентация предназначена для инженеров, аналитиков, менеджеров программ и менеджеров по продуктам, которые заинтересованы в том, как компании полагаются на платформу человеческой оценки Mechanical Turk для лучшего понимания контента и улучшения алгоритмов машинного обучения. Обсуждение сосредоточено на анализе и продуктовых решениях, связанных с созданием высококачественной системы краудсорсинга, которая использует преимущества мощного рабочего сообщества Mechanical Turk.
Сеансы обслуживания: архитектура и лучшие практики
Включает Amazon EMR, Amazon Athena, Amazon Kinesis, AWS Glue, Amazon QuickSight, Amazon Redshift, Amazon Elasticsearch Service и Amazon DynamoDB.
ABD201 – Архитектурные шаблоны и передовой опыт работы с большими данными на AWS
На этом занятии мы упростим обработку больших данных в виде шины данных, состоящей из различных этапов: сбор, хранение, обработка, анализ и визуализация. Далее мы обсудим, как выбрать правильную технологию на каждом этапе на основе таких критериев, как структура данных, задержка запросов, стоимость, частота запросов, размер элемента, объем данных, надежность и т. д.Наконец, мы предоставляем эталонные архитектуры, шаблоны проектирования и рекомендации по сборке этих технологий для решения ваших проблем с большими данными по оптимальной цене
Далее мы обсудим, как выбрать правильную технологию на каждом этапе на основе таких критериев, как структура данных, задержка запросов, стоимость, частота запросов, размер элемента, объем данных, надежность и т. д.Наконец, мы предоставляем эталонные архитектуры, шаблоны проектирования и рекомендации по сборке этих технологий для решения ваших проблем с большими данными по оптимальной цене
.
ABD202 – Передовой опыт создания бессерверных приложений для работы с большими данными
Бессерверные технологии позволяют быстро создавать и масштабировать приложения и службы без необходимости выделять серверы или управлять ими. На этом занятии мы покажем вам, как внедрить бессерверные концепции в ваши архитектуры больших данных.Мы изучаем концепции и преимущества бессерверных архитектур для больших данных, рассматривая шаблоны проектирования для приема, хранения, обработки и визуализации ваших данных. Попутно мы объясним, когда и как вы можете использовать бессерверные технологии для оптимизации обработки данных, минимизации управления инфраструктурой, повышения гибкости и надежности, а также поделиться эталонной архитектурой, используя сочетание облачных технологий и технологий с открытым исходным кодом для решения ваших проблем с большими данными. Темы включают: варианты использования и лучшие практики для бессерверных приложений больших данных; использование таких технологий AWS, как Amazon DynamoDB, Amazon S3, Amazon Kinesis, AWS Lambda, Amazon Athena и Amazon EMR; и бессерверный ETL, обработка событий, специальный анализ и аналитика в реальном времени.
Темы включают: варианты использования и лучшие практики для бессерверных приложений больших данных; использование таких технологий AWS, как Amazon DynamoDB, Amazon S3, Amazon Kinesis, AWS Lambda, Amazon Athena и Amazon EMR; и бессерверный ETL, обработка событий, специальный анализ и аналитика в реальном времени.
ABD206 – Создание визуализаций и информационных панелей с помощью Amazon QuickSight
Точно так же, как изображение стоит тысячи слов, изображение стоит тысячи точек данных. Ключевым аспектом нашей способности получать информацию из наших данных является поиск шаблонов, и эти шаблоны часто не очевидны, когда мы просто смотрим на данные в таблицах. Правильная визуализация поможет вам получить более глубокое понимание в гораздо более короткие сроки. На этом занятии мы покажем вам, как быстро и легко визуализировать данные с помощью Amazon QuickSight.Мы покажем вам, как вы можете подключаться к источникам данных, генерировать пользовательские показатели и расчеты, создавать комплексные бизнес-панели с различными типами диаграмм, а также настраивать фильтры и детализировать данные, чтобы нарезать их.
ABD203 – Приложения для потоковой передачи в реальном времени на AWS: варианты использования и шаблоны
Чтобы добиться успеха на рынке и обеспечить дифференцированное обслуживание клиентов, компаниям необходимо иметь возможность использовать оперативные данные в режиме реального времени, чтобы ускорить принятие решений.На этом занятии вы изучите распространенные варианты использования и архитектуры потоковой обработки данных. Сначала мы даем обзор потоковой передачи данных и возможностей потоковой передачи данных AWS. Далее мы рассмотрим несколько примеров клиентов и их потоковые приложения в реальном времени. Наконец, мы рассмотрим общие архитектуры и шаблоны проектирования наиболее популярных вариантов использования потоковых данных.
ABD213 – Как создать озеро данных с помощью каталога данных AWS Glue
По мере того, как объемы данных растут, а клиенты хранят все больше данных в AWS, у них часто появляются ценные данные, которые нелегко обнаружить и которые невозможно использовать для аналитики. Каталог данных AWS Glue обеспечивает централизованное представление вашего озера данных, делая данные легко доступными для аналитики. Мы представляем основные функции каталога данных AWS Glue и примеры его использования. Узнайте, как сканеры могут автоматически обнаруживать ваши данные, извлекать соответствующие метаданные и добавлять их в качестве определений таблиц в каталог данных AWS Glue. Мы также рассмотрим интеграцию каталога данных AWS Glue с Amazon Athena, Amazon EMR и Amazon Redshift Spectrum.
Каталог данных AWS Glue обеспечивает централизованное представление вашего озера данных, делая данные легко доступными для аналитики. Мы представляем основные функции каталога данных AWS Glue и примеры его использования. Узнайте, как сканеры могут автоматически обнаруживать ваши данные, извлекать соответствующие метаданные и добавлять их в качестве определений таблиц в каталог данных AWS Glue. Мы также рассмотрим интеграцию каталога данных AWS Glue с Amazon Athena, Amazon EMR и Amazon Redshift Spectrum.
ABD214 – Аналитика пользователей в режиме реального времени для мобильных и веб-приложений с помощью Amazon Pinpoint
Поскольку клиентам требуются релевантные и актуальные возможности в режиме реального времени на различных устройствах, цифровые компании стремятся собирать пользовательские данные в масштабе, анализировать эти данные , и мгновенно реагировать на потребности клиентов.Для этого требуются инструменты, которые могут записывать большие объемы пользовательских данных в структурированном виде, а затем мгновенно делать эти данные доступными для получения информации. На этом занятии мы покажем, как можно использовать Amazon Pinpoint для структурированного, но гибкого сбора пользовательских данных. Далее мы демонстрируем, как можно настроить эти данные для мгновенного использования с помощью таких сервисов, как Amazon Kinesis Firehose и Amazon Redshift. Мы рассмотрим примеры данных, основанные на реальных сценариях, чтобы проиллюстрировать, как Amazon Pinpoint позволяет легко организовывать миллионы событий, записывать их в режиме реального времени и сохранять для дальнейшего анализа.
На этом занятии мы покажем, как можно использовать Amazon Pinpoint для структурированного, но гибкого сбора пользовательских данных. Далее мы демонстрируем, как можно настроить эти данные для мгновенного использования с помощью таких сервисов, как Amazon Kinesis Firehose и Amazon Redshift. Мы рассмотрим примеры данных, основанные на реальных сценариях, чтобы проиллюстрировать, как Amazon Pinpoint позволяет легко организовывать миллионы событий, записывать их в режиме реального времени и сохранять для дальнейшего анализа.
ABD223 – Новаторы в области ИТ: новая технология использования данных для обеспечения гибкости, инноваций и оптимизации бизнеса
Компании всех размеров ищут технологии для эффективного использования данных и своих инвестиций в ИТ, чтобы оставаться конкурентоспособными и понимать, где их найти новый рост. Независимо от того, где компании находятся на своем пути к данным, они сталкиваются с более высокими требованиями к информации со стороны клиентов, потенциальных клиентов, партнеров, поставщиков и сотрудников. Все заинтересованные стороны внутри и за пределами организации хотят получать информацию по запросу или в режиме реального времени, доступную в любом месте на любом устройстве. Они хотят использовать его для оптимизации бизнес-результатов, не полагаясь на сложные программные инструменты или людей-привратников для получения соответствующей информации. Узнайте, как ИТ-новаторы в таких компаниях, как MasterCard, Jefferson Health и TELUS, используют Domo Business Cloud, чтобы помочь своим организациям более эффективно использовать данные в масштабе.
Все заинтересованные стороны внутри и за пределами организации хотят получать информацию по запросу или в режиме реального времени, доступную в любом месте на любом устройстве. Они хотят использовать его для оптимизации бизнес-результатов, не полагаясь на сложные программные инструменты или людей-привратников для получения соответствующей информации. Узнайте, как ИТ-новаторы в таких компаниях, как MasterCard, Jefferson Health и TELUS, используют Domo Business Cloud, чтобы помочь своим организациям более эффективно использовать данные в масштабе.
ABD301 – Анализ потоковых данных в режиме реального времени с помощью Amazon Kinesis
Amazon Kinesis позволяет легко собирать, обрабатывать и анализировать потоковые данные в режиме реального времени, чтобы вы могли получать своевременную аналитическую информацию и быстро реагировать на новую информацию.В этом сеансе мы представляем комплексное решение для потоковой передачи данных, использующее Kinesis Streams для приема данных, Kinesis Analytics для обработки в реальном времени и Kinesis Firehose для сохраняемости. Мы подробно рассмотрим, как писать SQL-запросы с использованием потоковых данных, и обсудим передовые методы оптимизации и мониторинга ваших приложений Kinesis Analytics. Наконец, мы обсудим, как оценить стоимость всей системы
Мы подробно рассмотрим, как писать SQL-запросы с использованием потоковых данных, и обсудим передовые методы оптимизации и мониторинга ваших приложений Kinesis Analytics. Наконец, мы обсудим, как оценить стоимость всей системы
.
ABD302 – Исследование и аналитика данных в режиме реального времени с помощью Amazon Elasticsearch Service и Kibana
На этом занятии в качестве примера мы используем веб-журналы Apache и покажем вам, как создать сквозное аналитическое решение.Сначала мы расскажем, как настроить кластер Amazon ES и получать данные с помощью Amazon Kinesis Firehose. Мы рассмотрим рекомендации по выбору типов экземпляров, вариантов хранения, количества сегментов и чередования индексов в зависимости от пропускной способности входящих данных. Затем мы покажем, как настроить информационную панель Kibana и создать собственные виджеты информационной панели. Наконец, мы рассматриваем подходы к созданию настраиваемых специальных отчетов.
ABD304 – Передовой опыт по хранению данных с помощью Amazon Redshift и Redshift Spectrum
Большинство компаний перегружены данными, но им не хватает важной информации для принятия своевременных и точных бизнес-решений.Они упускают возможность объединить большие объемы новых неструктурированных больших данных, которые находятся за пределами их хранилища данных, с надежными структурированными данными внутри своего хранилища данных. На этом занятии мы подробно рассмотрим, как современные хранилища данных объединяют и анализируют все ваши данные внутри и за пределами вашего хранилища данных без перемещения данных, чтобы дать вам более глубокое понимание для ведения вашего бизнеса. Мы расскажем о передовых методах проектирования оптимальных схем, эффективной загрузки данных и оптимизации ваших запросов для обеспечения высокой пропускной способности и производительности.
ABD305 – Шаблоны проектирования и рекомендации по анализу данных с помощью Amazon EMR
Amazon EMR — один из крупнейших операторов Hadoop в мире, который позволяет клиентам запускать ETL, машинное обучение, обработку в реальном времени, наука о данных и SQL с малой задержкой в петабайтном масштабе.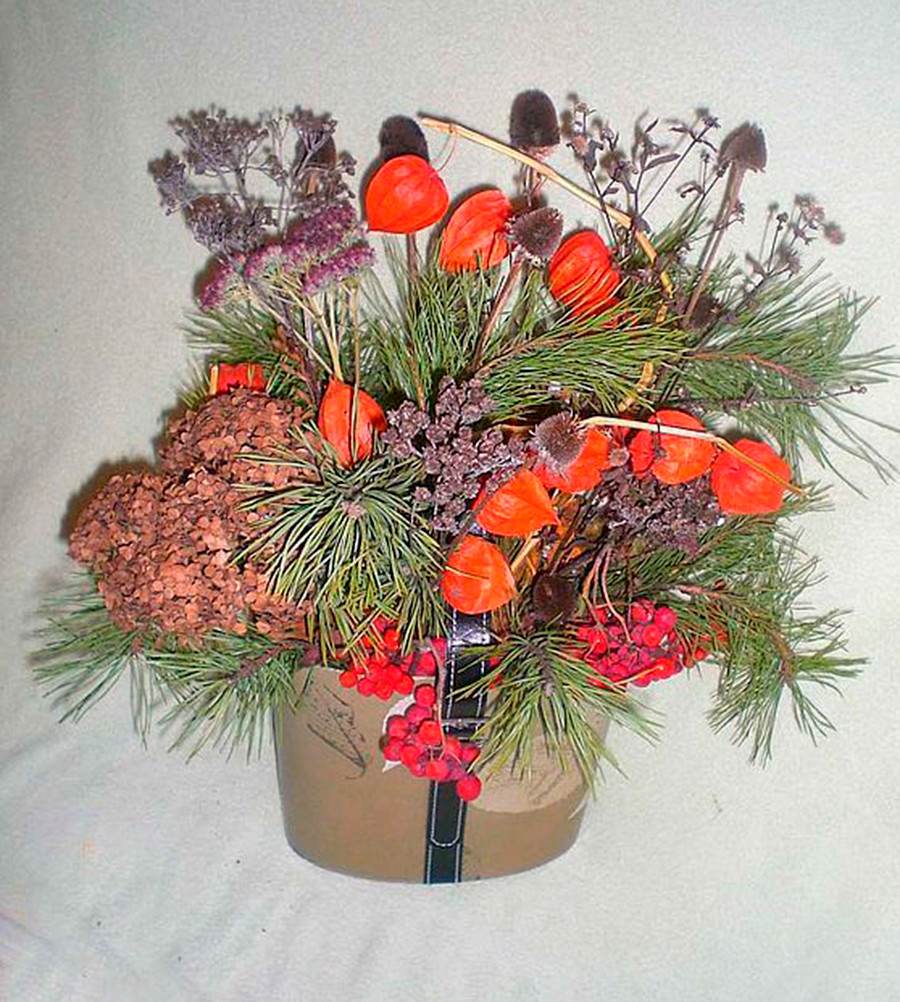 На этом занятии мы познакомим вас с шаблонами проектирования Amazon EMR, такими как использование Amazon S3 вместо HDFS, использование преимуществ как долгоживущих, так и недолговечных кластеров, а также с другими передовыми методами архитектуры Amazon EMR.Мы говорим о снижении затрат с помощью автоматического масштабирования и спотовых инстансов, а также о передовых методах обеспечения безопасности для шифрования и точного контроля доступа. Наконец, мы углубимся в некоторые из наших недавних запусков, чтобы держать вас в курсе наших последних функций.
На этом занятии мы познакомим вас с шаблонами проектирования Amazon EMR, такими как использование Amazon S3 вместо HDFS, использование преимуществ как долгоживущих, так и недолговечных кластеров, а также с другими передовыми методами архитектуры Amazon EMR.Мы говорим о снижении затрат с помощью автоматического масштабирования и спотовых инстансов, а также о передовых методах обеспечения безопасности для шифрования и точного контроля доступа. Наконец, мы углубимся в некоторые из наших недавних запусков, чтобы держать вас в курсе наших последних функций.
ABD307 – Глубокая аналитика для глобальной маркетинговой организации AWS
Чтобы удовлетворить потребности глобальной маркетинговой организации, команда маркетинговой аналитики AWS создала масштабируемую платформу, которая позволяет группе специалистов по обработке и анализу данных создавать настраиваемые эконометрические модели и модели машинного обучения для конечных пользователей. самообслуживание пользователей. Чтобы соответствовать стандартам безопасности данных, мы используем сквозное шифрование данных и различные сервисы AWS, такие как Amazon Redshift, Amazon RDS, Amazon S3, Amazon EMR с Apache Spark и Auto Scaling. На этом занятии вы увидите реальные примеры того, как мы масштабируем и автоматизируем критический анализ, например, рассчитываем влияние маркетинговых программ, таких как re:Invent, и расставляем приоритеты потенциальных клиентов для наших отделов продаж.
Чтобы соответствовать стандартам безопасности данных, мы используем сквозное шифрование данных и различные сервисы AWS, такие как Amazon Redshift, Amazon RDS, Amazon S3, Amazon EMR с Apache Spark и Auto Scaling. На этом занятии вы увидите реальные примеры того, как мы масштабируем и автоматизируем критический анализ, например, рассчитываем влияние маркетинговых программ, таких как re:Invent, и расставляем приоритеты потенциальных клиентов для наших отделов продаж.
ABD311 – Развертывание бизнес-аналитики в масштабе предприятия с помощью Amazon QuickSight
Один из самых больших компромиссов, на который обычно идут клиенты при масштабном развертывании решений бизнес-аналитики, — это гибкость по сравнению с управляемостью.На проектирование и развертывание крупномасштабных внедрений бизнес-аналитики с правильной структурой управления могут уйти месяцы. На этом занятии вы узнаете, как избежать этого компромисса с помощью Amazon QuickSight. Узнайте, как легко развернуть Amazon QuickSight для тысяч пользователей с помощью Active Directory и федеративной системы единого входа, обеспечивая при этом безопасный доступ к источникам данных в Amazon VPC или локально. Мы также расскажем, как управлять доступом к вашим наборам данных, внедрять безопасность на уровне строк, создавать запланированные отчеты по электронной почте и проверять доступ к вашим данным.
Узнайте, как легко развернуть Amazon QuickSight для тысяч пользователей с помощью Active Directory и федеративной системы единого входа, обеспечивая при этом безопасный доступ к источникам данных в Amazon VPC или локально. Мы также расскажем, как управлять доступом к вашим наборам данных, внедрять безопасность на уровне строк, создавать запланированные отчеты по электронной почте и проверять доступ к вашим данным.
ABD315 – Построение бессерверных конвейеров ETL с помощью AWS Glue
Организациям необходимо получать информацию и знания из растущего числа источников Интернета вещей (IoT), API, потоков кликов, неструктурированных и журнальных источников данных. Однако организации также часто ограничены устаревшими хранилищами данных и процессами ETL, которые были разработаны для транзакционных данных. В этом сеансе мы представим ключевые функции ETL AWS Glue, рассмотрим распространенные варианты использования, начиная от запланированных ночных загрузок хранилища данных и заканчивая потоками ETL, управляемыми событиями, практически в реальном времени для вашего озера данных. Мы обсудим, как создавать масштабируемые, эффективные и бессерверные конвейеры ETL с помощью AWS Glue. Кроме того, Merck расскажет, как они построили сквозной конвейер ETL для своей системы управления выпуском приложений и запустили его в производство менее чем за неделю с помощью AWS Glue.
Мы обсудим, как создавать масштабируемые, эффективные и бессерверные конвейеры ETL с помощью AWS Glue. Кроме того, Merck расскажет, как они построили сквозной конвейер ETL для своей системы управления выпуском приложений и запустили его в производство менее чем за неделю с помощью AWS Glue.
ABD318 – Создание озера данных с помощью Amazon S3, Amazon Kinesis и Amazon Athena
Узнайте, как создать озеро данных, в котором различные команды в вашей организации могут публиковать и использовать данные в режиме самообслуживания.Поскольку организации стремятся стать более ориентированными на данные, командам специалистов по обработке данных необходимо создавать архитектуры, способные удовлетворить потребности самых разных пользователей — от разработчиков до бизнес-аналитиков и специалистов по обработке и анализу данных. Каждая из этих групп пользователей использует разные инструменты, у них разные потребности в данных и разные способы доступа к данным. В этом докладе мы подробно рассмотрим создание озера данных с использованием Amazon S3, Amazon Kinesis, Amazon Athena, Amazon EMR и AWS Glue. В сессии примет участие Мохит Рао, руководитель отдела архитектуры и интеграции компании Atlassian, производителя таких продуктов, как JIRA, Confluence и Stride.Во-первых, мы рассмотрим пару распространенных архитектур для создания озера данных. Затем мы покажем, как Atlassian создала озеро данных самообслуживания, где любая команда внутри компании может опубликовать набор данных, который будет использоваться широким кругом пользователей.
В этом докладе мы подробно рассмотрим создание озера данных с использованием Amazon S3, Amazon Kinesis, Amazon Athena, Amazon EMR и AWS Glue. В сессии примет участие Мохит Рао, руководитель отдела архитектуры и интеграции компании Atlassian, производителя таких продуктов, как JIRA, Confluence и Stride.Во-первых, мы рассмотрим пару распространенных архитектур для создания озера данных. Затем мы покажем, как Atlassian создала озеро данных самообслуживания, где любая команда внутри компании может опубликовать набор данных, который будет использоваться широким кругом пользователей.
ABD 323 Расширение аналитики за пределы хранилища данных
У компаний есть ценные данные, которые они могут не анализировать из-за сложности, масштабируемости и проблем с производительностью при загрузке данных в их хранилище данных.Однако с помощью правильных инструментов вы можете расширить свою аналитику, чтобы запрашивать данные в своем озере данных — без необходимости загрузки.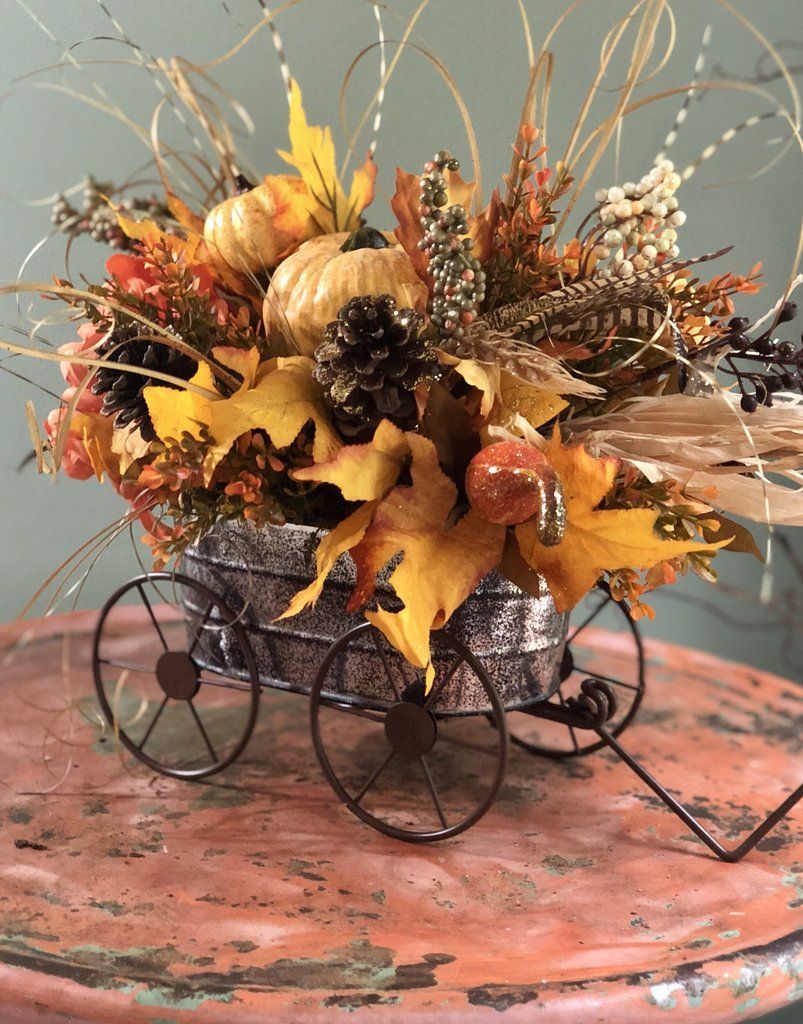 Amazon Redshift Spectrum расширяет аналитические возможности Amazon Redshift за пределы данных, хранящихся в вашем хранилище данных, и позволяет напрямую выполнять SQL-запросы к огромным объемам неструктурированных данных в вашем озере данных Amazon S3. Это дает вам свободу хранить ваши данные там, где вы хотите, в нужном вам формате, и иметь их доступными для аналитики, когда вам это нужно. Присоединяйтесь к обсуждению с архитекторами решений AWS, чтобы задать вопрос.
Amazon Redshift Spectrum расширяет аналитические возможности Amazon Redshift за пределы данных, хранящихся в вашем хранилище данных, и позволяет напрямую выполнять SQL-запросы к огромным объемам неструктурированных данных в вашем озере данных Amazon S3. Это дает вам свободу хранить ваши данные там, где вы хотите, в нужном вам формате, и иметь их доступными для аналитики, когда вам это нужно. Присоединяйтесь к обсуждению с архитекторами решений AWS, чтобы задать вопрос.
ABD330 – Объединение пакетной и потоковой обработки для получения лучшего из двух подходов
Сегодня многие архитекторы и разработчики стремятся создавать решения, объединяющие пакетную обработку данных и обработку данных в реальном времени и обеспечивающие лучшее из обоих подходов. Лямбда-архитектура (не путать с сервисом AWS Lambda) — это шаблон проектирования, который использует как пакетную обработку, так и обработку в реальном времени в рамках одного решения, чтобы удовлетворить требования к задержке, точности и пропускной способности в сценариях использования больших данных. Присоединяйтесь к нам, чтобы обсудить, как реализовать архитектуру Lambda (уровни пакетной обработки, скорости и обслуживания), а также передовые методы обработки данных, загрузки и настройки производительности
Присоединяйтесь к нам, чтобы обсудить, как реализовать архитектуру Lambda (уровни пакетной обработки, скорости и обслуживания), а также передовые методы обработки данных, загрузки и настройки производительности
.
ABD335 – Обнаружение аномалий в режиме реального времени с помощью Amazon Kinesis
Amazon Kinesis Analytics предлагает встроенный алгоритм машинного обучения, который можно использовать для простого обнаружения аномалий в сетевом трафике вашего VPC и улучшения мониторинга безопасности. Присоединяйтесь к нам, чтобы принять участие в интерактивном обсуждении того, как передавать журналы потоков VPC в Amazon Kinesis Streams и выявлять аномалии с помощью Kinesis Analytics.
ABD339 – Подробное описание и передовой опыт для Amazon Athena
Amazon Athena — интерактивный сервис запросов, который позволяет обрабатывать данные непосредственно из Amazon S3 без использования инфраструктуры. С момента его запуска на re:invent 2016 несколько организаций приняли Athena в качестве основного инструмента для обработки всех своих данных. В этом выступлении мы подробно рассмотрим наиболее распространенные варианты использования, в том числе работу с другими сервисами AWS. Мы рассматриваем лучшие практики создания таблиц и разделов, а также оптимизацию производительности.Мы также углубимся в то, как Athena обеспечивает безопасность, авторизацию и аутентификацию. Наконец, мы получили сообщение от клиента, который сократил затраты и сократил время выхода на рынок, развернув Athena в своей организации.
С момента его запуска на re:invent 2016 несколько организаций приняли Athena в качестве основного инструмента для обработки всех своих данных. В этом выступлении мы подробно рассмотрим наиболее распространенные варианты использования, в том числе работу с другими сервисами AWS. Мы рассматриваем лучшие практики создания таблиц и разделов, а также оптимизацию производительности.Мы также углубимся в то, как Athena обеспечивает безопасность, авторизацию и аутентификацию. Наконец, мы получили сообщение от клиента, который сократил затраты и сократил время выхода на рынок, развернув Athena в своей организации.
Ждем вас на re:Invent 2017!
Об авторе
Рой Бен-Альта — архитектор решений и главный менеджер по развитию бизнеса в Amazon Web Services в Нью-Йорке. Он занимается аналитикой данных и технологиями машинного обучения, работая с клиентами AWS над созданием инновационных продуктов, основанных на данных.
Учебное пособие по ELK Stack — Начало работы с ELK Stack
По мере того, как все больше и больше ИТ-инфраструктур переходят в облако, потребность в общедоступных облачных средствах безопасности и платформах для анализа журналов также быстро растет. Независимо от размера организации ежедневно генерируется огромное количество данных. Значительная часть этих данных состоит из журналов веб-сервера компании. Журналы являются одним из наиболее важных источников информации, которым часто пренебрегают.Каждый файл журнала содержит бесценную информацию, которая в основном неструктурирована и не имеет смысла. Без тщательного и подробного анализа этих данных журнала организация может не обращать внимания как на возможности, так и на окружающие ее угрозы. Вот где инструменты анализа журнала пригодятся. ELK Stack или Elastic Stack — это комплексное решение для анализа журналов, которое помогает в глубоком поиске , анализе и визуализации журнала, созданного на разных машинах.В этом блоге, посвященном учебному пособию по ELK Stack, я расскажу вам об этом.
Независимо от размера организации ежедневно генерируется огромное количество данных. Значительная часть этих данных состоит из журналов веб-сервера компании. Журналы являются одним из наиболее важных источников информации, которым часто пренебрегают.Каждый файл журнала содержит бесценную информацию, которая в основном неструктурирована и не имеет смысла. Без тщательного и подробного анализа этих данных журнала организация может не обращать внимания как на возможности, так и на окружающие ее угрозы. Вот где инструменты анализа журнала пригодятся. ELK Stack или Elastic Stack — это комплексное решение для анализа журналов, которое помогает в глубоком поиске , анализе и визуализации журнала, созданного на разных машинах.В этом блоге, посвященном учебному пособию по ELK Stack, я расскажу вам об этом.
Но прежде чем я начну, позвольте мне перечислить темы, которые я буду обсуждать:
Вы можете просмотреть эту запись учебного пособия по ELK, где наш эксперт по обучению стеку ELK подробно объяснил темы с примерами, которые помогут вам лучше понять эту концепцию.
ELK Учебник | Edureka
Этот учебник Edureka о том, что такое ELK Stack, поможет вам понять основы Elasticsearch, Logstash и Kibana вместе и поможет вам создать прочную основу в ELK Stack.
Итак, давайте быстро начнем с этого блога ELK Stack Tutorial, сначала разобравшись, что такое ELK Stack.
Что такое стек ELK? – ELK Stack Tutorial
Широко известный как ELK Stack, недавно был переименован в Elastic Stack. Это мощная коллекция из трех инструментов с открытым исходным кодом: Elasticsearch, Logstash и Kibana.
Эти три различных продукта чаще всего используются вместе для анализа журналов в различных ИТ-средах.Используя стек ELK, вы можете выполнять централизованное ведение журнала, что помогает выявлять проблемы с веб-серверами или приложениями. Он позволяет выполнять поиск по всем журналам в одном месте и выявлять проблемы, охватывающие несколько серверов, путем сопоставления их журналов в течение определенного периода времени.
Он позволяет выполнять поиск по всем журналам в одном месте и выявлять проблемы, охватывающие несколько серверов, путем сопоставления их журналов в течение определенного периода времени.
Теперь давайте подробно обсудим каждый из этих инструментов.
Logstash
Logstash — это конвейер сбора данных. Это первый компонент стека ELK, который собирает входные данные и передает их в Elasticsearch.Он одновременно собирает различные типы данных из разных источников и сразу делает их доступными для дальнейшего использования.
Elasticsearch
Elasticsearch — это база данных NoSQL, основанная на поисковой системе Lucene и созданная с помощью RESTful API. Это очень гибкая и распределенная система поиска и аналитики. Кроме того, он обеспечивает простое развертывание, максимальную надежность и простое управление благодаря горизонтальной масштабируемости. Он предоставляет расширенные запросы для выполнения подробного анализа и централизованно хранит все данные для быстрого поиска документов.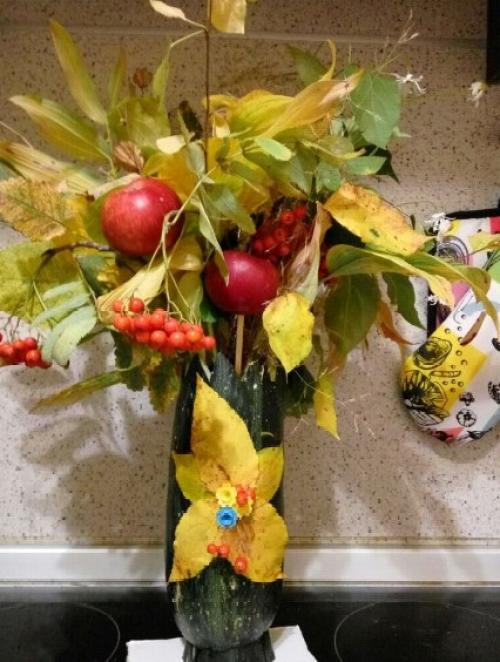
Kibana
Kibana — инструмент визуализации данных. Он используется для визуализации документов Elasticsearch и помогает разработчикам сразу понять их. Панель инструментов Kibana предоставляет различные интерактивные диаграммы, геопространственные данные, временные шкалы и графики для визуализации сложных запросов, выполняемых с помощью Elasticsearch. С помощью Kibana вы можете создавать и сохранять собственные графики в соответствии с вашими потребностями.
В следующем разделе этого блога учебного пособия по ELK Stack будет рассказано об архитектуре ELK Stack и о том, как в нем передаются данные.
Архитектура стека ELK — Учебное пособие по стеку ELK
Ниже приведена архитектура стека ELK, которая показывает правильный порядок потока журналов в ELK. Здесь журналы, созданные из различных источников, собираются и обрабатываются Logstash на основе предоставленных критериев фильтрации. Затем Logstash передает эти журналы в Elasticsearch, который затем анализирует и ищет данные. Наконец, с помощью Kibana журналы визуализируются и управляются в соответствии с требованиями.
Затем Logstash передает эти журналы в Elasticsearch, который затем анализирует и ищет данные. Наконец, с помощью Kibana журналы визуализируются и управляются в соответствии с требованиями.
Установка ELK Stack — Учебное пособие по ELK Stack
ШАГ I: Перейдите на https://www.elastic.co/downloads.
ШАГ II: Выберите и загрузите Elasticsearch.
ШАГ III: Выберите и загрузите Kibana.
ШАГ IV: Выберите и загрузите Logstash.
ШАГ V: Разархивируйте все три файла , чтобы получить файлы их папок.
Установка Elasticsearch
ШАГ VI: Теперь откройте папку elasticsearch и перейдите в папку bin .
ШАГ VII: Дважды щелкните файл elasticsearch.bat, чтобы запустить сервер elasticsearch.
ШАГ VIII: Дождитесь запуска сервера elasticsearch.
ШАГ IX: Чтобы проверить, запущен ли сервер, перейдите в браузер и введите localhost:9200 .
Установка Kibana
ШАГ X: Теперь откройте папку kibana и перейдите в ее папку bin .
ШАГ XI: Дважды щелкните по кибане.bat для запуска сервера elasticsearch.
ШАГ XII: Дождитесь запуска сервера kibana.
ШАГ XIII: Чтобы проверить, запущен ли сервер, перейдите в браузер и введите localhost:5601 .
Установка Logstash
ШАГ XIV: Теперь откройте папку logstash.
ШАГ XV: Чтобы проверить установку logstash, откройте командную строку и перейдите в папку logstash.Теперь введите:
binlogstash -e 'input { stdin { } } output { stdout {} }' ШАГ XVI: Подождите, пока в командной строке не появится сообщение «Главный конвейер запущен».
ШАГ XVII: Теперь введите сообщение в командной строке и нажмите Enter.
ШАГ XVIII: Logstash добавляет к сообщению информацию об отметке времени и IP-адресе и отображает ее в командной строке.
Поскольку мы закончили установку, давайте теперь углубимся в эти инструменты.Начнем с Elasticsearch.
Elasticsearch — Учебное пособие по ELK Stack
Как упоминалось ранее, Elasticsearch — это поисковая система с высокой степенью масштабируемости, работающая поверх движка Lucene на основе Java. По сути, это база данных NoSQL; это означает, что он хранит данные в неструктурированном формате, и SQL-запросы не могут выполняться для любых транзакций. Другими словами, он хранит данные внутри документов, а не таблиц и схем. Чтобы иметь лучшее представление, проверьте следующую таблицу, которая показывает, что есть что, в Elasticsearch по сравнению с базой данных.
Давайте теперь познакомимся с основными понятиями Elasticsearch.
При работе с Elasticsearch необходимо выполнить три основных шага:
- Индексирование
- Отображение
- Поиск
Давайте поговорим о них подробно, один за другим.
Индексирование
Индексирование — это процесс добавления данных Elasticsearch. Это называется «индексированием», потому что когда данные вводятся в Elasticsearch, они помещаются в индексы Apache Lucene.Затем Elasticsearch использует эти индексы Lucene для хранения и извлечения данных. Индексирование аналогично процессу создания и обновления операций CRUD.
Схема индекса состоит из имени/типа/идентификатора, , где имя и тип являются обязательными полями. Если вы не предоставите идентификатор, Elasticsearch предоставит идентификатор самостоятельно. Затем весь этот запрос добавляется к HTTP-запросу PUT, и конечный URL-адрес выглядит следующим образом: Имя/тип/идентификатор PUT Вместе с полезной нагрузкой HTTP также отправляется документ JSON, содержащий поля и значения.
Ниже приведен пример создания документа клиента из США с его данными в полях.
PUT /клиент/США/1
{
"ИД": 101,
"FName": "Джеймс",
«LName» : «Попка»,
"Электронная почта": "[email protected]",
«Город»: «Новый Орлеан»,
"Тип": "ВИП"
} Это даст вам следующий вывод:
Здесь показано, что документ был создан и добавлен в индекс.
Теперь, если вы попытаетесь изменить данные поля без изменения идентификатора, Elasticsearch перезапишет ваш существующий документ текущими данными.
PUT /клиент/США/1
{
"ИД": 101,
"FName": "Джеймс",
«LName» : «Попка»,
«Электронная почта»: «[email protected]»,
«Город»: «Лос-Анджелес»,
"Тип": "ВВИП"
}
Здесь показано, что документ был обновлен новыми деталями индекса.
Сопоставление
Сопоставление — это процесс настройки схемы индекса. Сопоставляя, вы сообщаете Elasticsearch о типах данных атрибутов, присутствующих в вашей схеме.Если сопоставление не было выполнено для конкретного во время перед индексированием, Elasticsearch динамически добавит общий тип к этому полю. Но эти универсальные типы очень просты и в большинстве случаев не удовлетворяют ожиданиям запроса.
Теперь попробуем отобразить наш запрос.
ПУТ /заказчик/
{
"сопоставления": {
"НАС":{
"характеристики":{
"Я БЫ":{
"тип": "длинный"
},
"FName": {
"тип": "текст"
},
"Имя" : {
"тип": "текст"
},
"Электронное письмо" : {
"тип": "текст"
},
"Город" : {
"тип": "текст"
},
"Тип" : {
"тип": "текст"
}
}
}
}
}
При выполнении запроса вы получите вывод такого типа.
Поиск
Общий поисковый запрос с определенным индексом и типом будет выглядеть так: POST index/type/_search
Let now наш «клиентский» индекс.
POST /customer/US/_search
При выполнении этого запроса будет сгенерирован следующий результат:
Но если вы хотите найти конкретные результаты, Elasticsearch предлагает три способа, которыми вы можете это сделать:
С помощью запросов
С помощью запросов вы можете искать определенный документ или записи.Например, давайте выполним поисковый запрос для клиентов, которые попадают в категорию «VVIP».
POST /клиент/США/_поиск { "запрос": { "совпадение": { "Тип": "ВВИП" } } }
POST /customer/_search
{
"запрос": {
"совпадение": {
"Тип": "ВВИП"
}
},
"пост_фильтр": {
"совпадение" : {
"ИД": 101
}
}
} Если вы выполните этот запрос, вы получите следующий результат:
POST /customer/_search
{
"размер": 0,
"аггс" : {
"Cust_Types": {
«термины» : { «поле» : «Тип.ключевое слово" }
}
}
} Теперь посмотрим, как получить набор данных из индекса.
Получение данных
Чтобы проверить список документов, которые у вас есть в индексе, вам просто нужно отправить HTTP-запрос GET в следующем формате: GET index/type/id
Давайте попробуем получить сведения о клиенте с идентификатором, равным 2:
GET /customer/US/2
При успешном выполнении вы получите следующий результат.
С помощью Elasticsearch вы можете не только просматривать данные, но и удалять документы.
Удаление данных
Используя соглашение об удалении, вы можете легко удалить ненужные данные из вашего индекса и освободить место в памяти. Для удаления любого документа необходимо отправить HTTP-запрос DELETE в следующем формате: DELETE индекс/тип/идентификатор.
Теперь попробуем удалить данные клиента с идентификатором 2.
DELETE /customer/US/2
При выполнении этого запроса вы получите результат следующего типа.
Итак, на этом мы завершаем основы операций CRUD с использованием Elasticsearch. Знание этих основных операций поможет вам выполнять другие виды поиска, и вы достаточно хороши, чтобы продолжить изучение ELK Tutorial. Но если вы хотите подробно изучить Elasticsearch, вы можете обратиться к моему блогу Elasticsearch Tutorial.
Теперь давайте начнем со следующего инструмента ELK Stack, который называется Logstash.
Logstash — Учебное пособие по ELK Stack
Как я уже говорил, Logstash — это конвейерный инструмент, обычно используемый для сбора и пересылки журналов или событий. Это механизм сбора данных с открытым исходным кодом, который может динамически интегрировать данные из различных источников и нормализовать их в указанные места назначения.
Используя ряд входных, фильтрующих и выходных плагинов, Logstash позволяет легко преобразовывать различные события. По крайней мере, Logstash нуждается в плагине ввода и вывода, указанном в его конфигурационном файле, для выполнения преобразований.Ниже приведена структура конфигурационного файла Logstash:
input {
...
}
фильтр {
...
}
вывод {
...
} Как видите, весь файл конфигурации разделен на три раздела, и каждый из этих разделов содержит параметры конфигурации для одного или нескольких подключаемых модулей. Три раздела:
- вход
- фильтр
- вывод
Вы также можете применить более одного фильтра в файле конфигурации. В таких случаях порядок их применения будет таким же, как и порядок указания в конфиг-файле.
Давайте теперь попробуем настроить наш файл набора данных о клиентах в США, который находится в формате файла CSV.
вход{
файл{
путь => "E:/ELK/data/US_Customer_List.csv"
start_position => "начало"
поскольку db_path => "/dev/null"
}
}
фильтр{
csv {
разделитель => ","
columns =>["Cust_ID","Cust_Fname","Cust_Lname","Cust_Email","Cust_City","Cust_Type"]
}
mutate{convert => ["Cust_ID","integer"]}
}
вывод{
эластичный поиск {
хосты => "локальный хост"
индекс => "клиенты"
document_type => "US_Based_Cust"
}
стандартный вывод {}
} Чтобы вставить данные этого файла CSV в elasticsearch, вы должны уведомить сервер Logstash.
Для этого выполните следующие шаги:
- Откройте командную строку
- Перейдите в каталог bin Logstash
- Введите: logstash – f X :/foldername/config_filename.config 900 Как только ваш сервер logstash будет запущен и запущен, он начнет передавать ваши данные из файла в Elasticsearch.
Если вы хотите проверить, успешно ли были вставлены ваши данные, перейдите к плагину sense и введите:
GET /customers/
Это даст вам количество созданных документов.
Теперь, если вы хотите визуализировать эти данные, вам нужно использовать последний инструмент ELK Stack, то есть Kibana. Итак, в следующем разделе этого руководства по стеку ELK я расскажу о Kibana и способах его использования для визуализации ваших данных.
Kibana — Учебное пособие по ELK Stack
Как упоминалось ранее, Kibana — это инструмент визуализации и аналитики с открытым исходным кодом. Это помогает визуализировать данные, которые передаются Logstash и сохраняются в Elasticsearch. Вы можете использовать Kibana для поиска, просмотра и взаимодействия с этими сохраненными данными, а затем визуализировать их в различных диаграммах, таблицах и картах.Браузерный интерфейс Kibana упрощает работу с огромными объемами данных и отражает изменения в запросах Elasticsearch в реальном времени. Кроме того, вы можете легко создавать, настраивать, сохранять и делиться своими информационными панелями.
Как только вы научитесь работать с Elasticsearch и Logstash, использование Kibana перестанет быть проблемой. В этом разделе учебного блога ELK я познакомлю вас с различными функциями, которые вам понадобятся для анализа ваших данных.
Страница управления
Здесь вы должны выполнять настройки среды выполнения Kibana.На этой странице вам нужно указать несколько вещей для вашего поиска. См. следующий пример, в котором я настроил записи для своего индекса «клиент». Здесь, как вы видите, в поле «Шаблон индекса» вам нужно указать индекс, на котором вы хотите использовать. Убедитесь, что в поле «Имя поля фильтра времени» выбрано значение @timestamp. Затем вы можете продолжить и нажать «Создать», чтобы создать индекс. Если ваш индекс создан успешно, вы увидите следующий тип страницы: Здесь вы можете выбрать различные фильтры из раскрывающегося списка в соответствии с вашими требованиями.Кроме того, чтобы освободить память, вы также можете удалить определенный индекс.
Страница «Обнаружение»
На странице «Обнаружение» у вас есть доступ к каждому документу, представляющему каждый индекс, который соответствует выбранному шаблону индекса. Вы можете легко взаимодействовать и исследовать каждый бит данных, который присутствует на вашем сервере Kibana. Более того, вы можете просматривать данные, присутствующие в документах, и выполнять по ним поисковые запросы.
Ниже вы можете видеть, что я выполняю поиск «VIP» клиентов из «Лос-Анджелеса».
Итак, как видите, у нас есть только один VIP-клиент из Лос-Анджелеса.Страница визуализации
Страница визуализации позволяет визуализировать данные, представленные в ваших индексах Elasticsearch, в виде диаграмм, столбцов, круговых диаграмм и т. д. Здесь вы даже можете создавать информационные панели, которые будут отображать соответствующие визуализации. на основе запросов Elasticsearch. Как правило, для извлечения и обработки данных используется серия запросов агрегации Elasticsearch.Когда вы переходите на страницу визуализации и ищите сохраненные визуализации или можете создать новую.
Вы можете агрегировать свои данные в любой форме. Для удобства пользователей предусмотрены различные типы параметров визуализации. Позвольте мне показать вам, как вы можете визуализировать данные о клиентах в США на основе типов пользователей. Чтобы выполнить визуализацию, выполните следующие действия:
- Выберите тип визуализации. [Здесь я использую пирог]
- В поле агрегации выберите «термин» из раскрывающегося списка.
- В «поле» выберите тип поля, по которому вы хотите выполнить поиск.
- Вы также можете указать порядок и размер ваших визуализаций.
- Теперь нажмите кнопку «Выполнить», чтобы создать круговую диаграмму.
Страница панели мониторинга
На странице панели мониторинга отображается коллекция сохраненных визуализаций. Здесь вы можете либо добавить новые визуализации, либо использовать любую сохраненную визуализацию.
Страница Timelion
Timelion — это визуализатор данных временных рядов, который объединяет полностью независимые источники данных в единый интерфейс.Он управляется однострочным языком выражений, который используется для извлечения данных временных рядов, выполнения вычислений для упрощения сложных вопросов и визуализации результатов.
Страница инструментов разработчика
Страница инструментов разработчика Kibana содержит инструменты разработки, такие как плагин Beta Sense, который используется для взаимодействия с данными, присутствующими в Elasticsearch. Его часто называют консолью Кибаны. Ниже приведен пример, в котором я использовал плагин Kibana sense для поиска моего индекса «клиентов» с типом «US_based_cust»:
На этом я завершаю этот блог в учебнике по ELK Stack.Теперь вы готовы выполнять поиск и анализ любых данных с помощью Logstash, Elasticsearch и Kibana.
Если вы нашли этот учебный пособие по стогам 9090 Блог, актуален, Проверьте ELK Stack Training от Edureka, доверенная онлайн-обучающая компания с сетью более 250 000 удовлетворенных учеников Глобус. Курс обучения и сертификации Edureka ELK Stack помогает учащимся запускать и управлять собственным поисковым кластером с помощью Elasticsearch, Logstash и Kibana. Есть к нам вопрос? Пожалуйста, укажите это в разделе комментариев этого блога ELK Stack Tutorial, и мы свяжемся с вами как можно скорее.
Мониторинг Informix с помощью эластичного стека
Опубликовано: 8 декабря, 2018 | Автор: Бен Томпсон | Рубрики: Мониторинг | Теги: elasticsearch, elk, informix, kibana, logstash |
Введение
Если вы не знакомы с Elastic Stack, это набор продуктов для приема данных или журналов, поиска, анализа и визуализации.На веб-сайте Elastic есть хороший обзор того, как это можно собрать. Я говорю «может», потому что стек очень гибкий и, например, вы можете отправлять документы JSON в Elasticsearch через REST API, а не использовать Filebeat или Logstash.
Эта запись в блоге в основном посвящена загрузке онлайн-журнала Informix с помощью Filebeat, распознаванию определенных типов строк журнала, которые могут возникнуть, и маркировке файла с помощью правил, установленных в Logstash, перед его отправкой в Elasticsearch для хранения и индексации.Наконец, Kibana можно использовать для визуализации данных, хранящихся в Elasticsearch.
Легко понять, как это можно масштабировать, чтобы обеспечить единое место для визуализации журналов из нескольких экземпляров, и было бы довольно просто добавить и другие журналы, такие как журналы панели Informix и журналы из операционной системы.
На IIUG 2018 в Арлингтоне, штат Вирджиния, я представил доклад под названием DevOps для администраторов баз данных , в котором демонстрировался описанная ниже настройка Docker, но в то время я еще не задокументировал полную настройку.Вот!
Практическая демонстрация с контейнерами Docker
Обзор
В этой демонстрации настраиваются два контейнера: один с Informix Developer Edition и Filebeat для сбора и доставки журналов:
- Informix 12.10.FC12W1DE, прослушивание порта 9088/tcp для соединений onsoctcp .
- Filebeat 6.5.2.
и другие компоненты Elasticstack следующим образом:
- Логсташ 6.5.2, прослушивание порта 5044/tcp.
- Elasticsearch 6.5.2, прослушивание порта 9200/tcp.
- Kibana 6.5.2, прослушивание порта 5601/tcp.
Доступ к Kibana осуществляется через ваш любимый веб-браузер, работающий на вашем рабочем столе. Nginx будет прослушивать порт 80, поэтому вы можете просто получить доступ к http://localhost/
.
Для безопасной реализации в рабочей среде рекомендуется использовать Nginx с HTTPS в качестве обратного прокси-сервера для веб-службы Kibana, как показано на схеме. В этой демонстрации мы будем использовать Nginx, а не напрямую подключаться к Kibana, но не будем настраивать SSL; есть много руководств в Интернете о том, как это сделать.Также связь между Filebeat и Logstash должна быть зашифрована: этот пост в блоге не распространяется на это.
Приведенные выше версии актуальны на момент написания (декабрь 2018 г.). Elasticstack обновляется очень быстро, поэтому, скорее всего, к тому времени, когда вы будете это читать, это будут не самые последние версии. Идея этого сообщения в блоге заключается в том, что вы должны просто иметь возможность копировать и вставлять команды и получать работающую систему, но вы не должны удивляться, если что-то не работает идеально, если ваши версии не соответствуют приведенным выше.Например, в промежутке между началом и завершением этого поста в блоге была выпущена версия 6.5.x с улучшенными настройками безопасности по умолчанию, в которых службы прослушивали только петлевой интерфейс без перенастройки.
Для запуска всего Elasticstack в Docker плюс Informix требуется разумный объем памяти, и я бы посоветовал выделить для Docker Engine не менее 2,5 ГБ.
Докер-сеть
Чтобы обеспечить разрешение имен между контейнерами, мы собираемся начать с создания сети докеров:
создание сети докеров --driver bridge my_informix_elk_stack
Установка эластичного стека
Докер-контейнер
Мы начнем с настройки контейнера Elastic Stack Docker, который будет использоваться в (минимальной) установке Debian.В терминальном прогоне:
docker pull debian
docker run -it --name elasticstack_monitoring -p 80:80 -p 5044:5044 --hostname elasticstack -e "GF_SECURITY_ADMIN_PASSWORD=secret" --net my_informix_elk_stack debian
Теперь ваш терминал должен находиться внутри контейнера Docker и войти в систему как root.
Чтобы избежать некоторых проблем с debconf при установке пакетов, запустите:
echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
Установить Java
Запустите эти команды, чтобы установить пакет общих свойств программного обеспечения, а затем установите OpenJDK 8, который требуется для Elasticsearch и Logstash.Java 9 тоже подойдет.
Образ Debian Docker не поставляется со многими предустановленными пакетами, поэтому я также собираюсь установить vim для редактирования файлов позже, а также несколько других необходимых вещей; вы можете предпочесть nano или другой редактор.
apt-get update
apt-get install software-properties-common gnupg vim wget apt-transport-https openjdk-8-jre
Контейнер Debian Docker является базовой установкой, поэтому этот краткий список пакетов имеет сотни зависимостей.
Проверить версию Java:
# java -version
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (сборка 1.8.0_181-8u181-b13-2~deb9u1-b13)
OpenJDK 64-разрядная виртуальная машина сервера (сборка 25.181-b13,b13,b13,b13,b13)
Установить Elasticsearch
Установка Elasticsearch более проста, чем Oracle Java, и соответствует стандартным методам Linux для настройки и установки из стороннего репозитория программного обеспечения.
Сначала мы устанавливаем ключ репозитория:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | apt-ключ добавить -
Затем добавьте репозиторий:
эхо "deb https://artifacts.elastic.co/packages/6.x/apt стабильная основная" | тройник -a /etc/apt/sources.list.d/elastic-6.x.list
Нам необходимо установить транспортный пакет HTTPS, прежде чем мы сможем приступить к установке.
apt-get update
apt-get install elasticsearch
Elasticsearch будет работать прямо из коробки, что подходит для целей этой демонстрации, и (после того, как мы запустим службу) будет прослушивать на локальном хосте только порты 9200 для REST API и 9300 для связи с узлом.
Установить Кибану
Это установлено из репозитория Elasticstack, добавленного выше:
apt-get установить кибану
Опять же, Kibana не требует никакой перенастройки для целей этой демонстрации и будет прослушивать на локальном хосте только порт 5601.
Запустите Kibana, запустив:
служба запуска кибаны
Теперь, когда Kibana работает, запустите Elasticsearch, выполнив:
запуск сервиса elasticsearch
В связи с этим стоит отметить, что современные дистрибутивы Debian используют systemd, но это не работает в непривилегированных контейнерах Docker.Для справки, эквиваленты systemd для этого:
systemctl daemon-reload
systemctl enable kibana
systemctl enable elasticsearch
systemctl start kibana
systemctl start elasticsearch
Эти команды также обеспечивают запуск службы при загрузке.
Поскольку Kibana прослушивает только локальный хост и поэтому недоступен из внешнего веб-браузера, мы настроим Nginx в качестве обратного прокси-сервера. Это более безопасная конфигурация и рекомендуется для любой производственной реализации, поскольку только Nginx напрямую подключен к Интернету, а не Kibana.
Установите Nginx в качестве обратного прокси-сервера
Начните с установки Nginx:
apt-get установить nginx
Отредактируйте файл /etc/nginx/sites-available/default и в разделе location/ добавьте строку:
proxy_pass http://localhost:5601;
Закомментируйте строку, начинающуюся с try_files .
Это должно выглядеть примерно так:
местоположение / {
# Сначала пытаемся обслужить запрос как файл, затем
# в качестве каталога, затем вернуться к отображению 404.прокси_пароль http://localhost:5601;
#try_files $uri $uri/ =404;
} Не забудьте точку с запятой!
Запуск nginx:
запуск службы nginx
Установить Logstash
Процедура установки, которая уже должна выглядеть знакомой:
apt-получить установку logstash
Наша конфигурация Logstash будет состоять из двух частей:
- Стандартная готовая конфигурация для получения файлов из Filebeat и отправки их в Elasticsearch: для этой копии /etc/logstash/logstash-sample.conf с по /etc/logstash/conf.d/logstash.conf
- Пользовательский файл конфигурации /etc/logstash/conf.d/informix.conf для анализа онлайн-журнала Informix.
Я намерен обновить и улучшить конфигурацию Logstash для фильтрации онлайн-журнала Informix, и она доступна на моей странице Github по адресу https://github.com/skybet/informix-helpers/blob/master/logstash/informix.conf. Загрузите его локально, а затем скопируйте в свой контейнер Docker следующим образом:
.
докер cp informix.conf elasticstack_monitoring:/etc/logstash/conf.d/informix.conf
Файл конфигурации Informix требует, чтобы Filebeat пометил файл тегом « [поле][informix] = true »; это условие тривиально удалить, если вы хотите.
Проверьте конфигурацию Logstash с помощью:
/usr/share/logstash/bin/logstash -t --path.settings /etc/logstash
Наконец, запустите Logstash с:
/usr/share/logstash/bin/logstash --path.settings /etc/logstash
Вы также можете использовать systemd для этого.
Установка Informix
Контейнер Docker Informix Developer Edition
Теперь мы настроим контейнер Informix для мониторинга. На вашей рабочей станции в другом терминале запустите:
$ docker pull ibmcom/informix-developer-database
docker run -it --name iif_developer_edition --привилегированный -p 9088:9088 -p 9089:9089 -p 27017:27017 -p 27018:27018 -p 27883:27883 - -hostname ifxserver --net my_informix_elk_stack -e LICENSE=accept ibmcom/informix-developer-database:latest
Стоит отметить, что если вы выйдете из оболочки, контейнер Informix DE Docker остановится.Вы можете начать его снова с:
запуск докера iif_developer_edition -i
Эта последняя версия, содержащая 12.10.FC12W1, не возвращает вас к подсказке после запуска ядра, поэтому вам нужно будет открыть интерактивный контейнер в другом окне терминала следующим образом:
docker exec -it iif_developer_edition /bin/bash
Теперь оба контейнера Docker запущены, и вы сможете проверить разрешение имен и подключение в обоих направлениях с помощью ping.
Из контейнера Informix:
informix@ifxserver:/$ ping elasticstack_monitoring
Из контейнера Elastic Stack:
root@elasticstack2:/# ping iif_developer_edition
Эти имена принадлежат контейнерам и не обязательно являются их именами узлов.
Пока вы все еще вошли в систему, поскольку Informix установите MSG_DATE в 1, что требуется для моей конфигурации Logstash:
onmode -wf MSG_DATE=1
Это означает, что (почти) все сообщения онлайн-журнала будут начинаться с даты (в формате ММ/ДД/ГГ) и времени (в формате ЧЧ:ММ:СС).
Вы войдете в систему как пользователь informix , который может sudo получить права root следующим образом:
sudo -i
Установить Filebeat
В контейнере Informix все равно, что установить Filebeat:
apt-get update
apt-get install vim wget apt-transport-https
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | тройник -a /etc/apt/источники.list.d/elastic-6.x.list
apt-get update
apt-get install filebeat
Файл конфигурации Filebeat — /etc/filebeat/filebeat.yml . Если вы не знакомы с файлами yml , правильный отступ с двумя пробелами на уровень абсолютно необходим; файлы yml полагаются на это для структуры, а не на какие-либо фигурные скобки или квадратные скобки. Строки, начинающиеся с тире, обозначают массив.
onstat -c | grep MSGPATH показывает, что файл оперативного журнала Informix находится по адресу /opt/ibm/data/logs/online.log , и мы хотим, чтобы Filebeat обработал его и передал Logstash, работающему в другом контейнере, для анализа.
Онлайн-журнал Informix довольно часто содержит строки с переносом, и они, как правило, не начинаются ни с какой отметки времени или даты.
Отредактируйте файл и добавьте следующую конфигурацию непосредственно в filebeat.inputs :
- тип: журнал
включено: правда
пути:
- /opt/ibm/data/logs/online.log
поля:
Информикс: правда
многострочный.[0-9][0-9]'
многострочный.негат: правда
multiline.match: после Наконец, настройте вывод, закомментировав (добавив «#») все части output.elasticsearch и раскомментировав раздел output.logstash . Установите хостов в этом разделе на [«elasticstack_monitoring:5044»] .
Запустите filebeat, запустив:
запуск службы filebeat
Вы должны увидеть сообщение: Config OK .
Использование Кибаны
Теперь вы сможете войти в Kibana на http://localhost/ и добавить индекс на filebeat* .
Затем в разделе «Обнаружение» вы сможете увидеть строки журнала Informix, поступающие в систему, и то, как они были помечены.
Если вы хотите улучшить и протестировать синтаксический анализ определенных записей журнала, достаточно просто создать их самостоятельно в контейнере Informix следующим образом:
echo "08.12.18 17:00:00 Моя строка журнала Informix" >> /opt/ibm/data/logs/online.log
Этот конкретный пост в блоге скоро закончится. Кибана — это большая тема, и на данном этапе моего путешествия по Elasticstack DevOps я не чувствую себя достаточно квалифицированным, чтобы вести блог на эту тему.Как только я продвинусь дальше, я могу сделать следующий пост.
Тегирование событий в онлайн-журнале, таких как продолжительность контрольной точки и ее назначение переменной informix.ckpt_duration , должно позволить вам легко выполнять поиск на основе этого и визуализировать их на информационных панелях.
Удачи!
Нравится:
Нравится Загрузка…
Связанные
Развертывание стека ELK с Ansible
Как человеческие существа, нам нравится верить, что каждый из нас особенный, и его нелегко заменить.Это может быть хорошо, но, пожалуйста, не привыкайте относиться к своему компьютеру таким же образом.
Ansible — это бесплатная программная платформа для настройки и управления компьютерами, и в последнее время я часто использую ее для управления стеком ELK. Elasticsearch, Logstash и Kibana.
Я могу определить список серверов, которыми я хочу управлять, в конфигурационном файле YAML — так называемая инвентаризация:
[упругий поиск-мастер]
es-master1.mydomain.com
эс-мастер2.мой домен.com
es-master3.mydomain.com
[данные эластичного поиска]
лось-data1.mydomain.com
лось-data2.mydomain.com
лось-data3.mydomain.com
[кибана]
kibana.mydomain.com
[elasticearch-master] es-master1.mydomain.com es-master2.mydomain.com es-master3.mydomain.com elkelk-data1.mydomaindata1 900 .com elk-data2.mydomain.com elk-data3.mydomain.com
[kibana] kibana.mydomain.com |
И определить роли для серверов в другом конфигурационном файле YAML — так называемом плейбуке:
— хосты: elasticsearch-master
роли:
— ansible-elasticsearch
— хосты: elasticsearch-данные
роли:
— ansible-elasticsearch
— хосты: logstash
роли:
— ansible-logstash
— хозяева: кибана
роли:
— ansible-кибана
. — ansible-logstash
— хосты: kibana roles: — ansible-kibana |
Каждая группа серверов может иметь свои файлы, содержащие переменные конфигурации.
elasticsearch_версия: 2.1.0
elasticsearch_node_master: ложь
elasticsearch_heap_size: 1000G
elasticsearch_version: 2.1.0 elasticsearch_node_master: false elasticsearch_heap_size: 1000G |
Ansible используется для настройки блока vagrant стека ELK по адресу https://github.com/comperiosearch/vagrant-elk-box-ansible, который недавно был обновлен с помощью Elasticsearch 2.1, Кибана 4.3 и Логсташ 2.1
Тот же набор ролей Ansible можно применять, когда конфигурацию необходимо перенести в рабочую среду, применяя другой набор переменных файлов с измененными именами хостов, сертификатами и т. д. Возможных способов сделать это несколько.
Как это работает?
Ansible не требует агента. Это означает, что вы не устанавливаете ничего (агента) на машины, которыми управляете. Ansible нужно только установить на управляющей машине (Linux/OSX) и подключиться к управляемым машинам (даже с некоторой поддержкой Windows) с помощью SSH.Единственным требованием к управляемым компьютерам является Python.
Счастливый брат!
Статья написана Кристофером Вигом
Старший консультант Comperio.